زبان کا ماڈل (LLM)
LLM ٹیب یہ طے کرتا ہے کہ آپ کا ایجنٹ کیسے سوچتا ہے اور اس کی وائس پائپ لائن کیسے جڑی ہوئی ہے۔ یہ وائس پائپ لائن موڈ (speech-to-text، زبان کا ماڈل اور text-to-speech کس طرح ایک ساتھ فٹ ہوتے ہیں)، کون سا LLM فراہم کنندہ اور ماڈل گفتگو چلاتے ہیں، جنریشن پیرامیٹرز، ایک فال بیک ماڈل، اور RAG / نالج بیس کے ربط کو کنٹرول کرتا ہے۔ اسے ایجنٹ بلڈر میں /agent/setup پر سیٹ کریں۔
وائس پائپ لائن موڈ
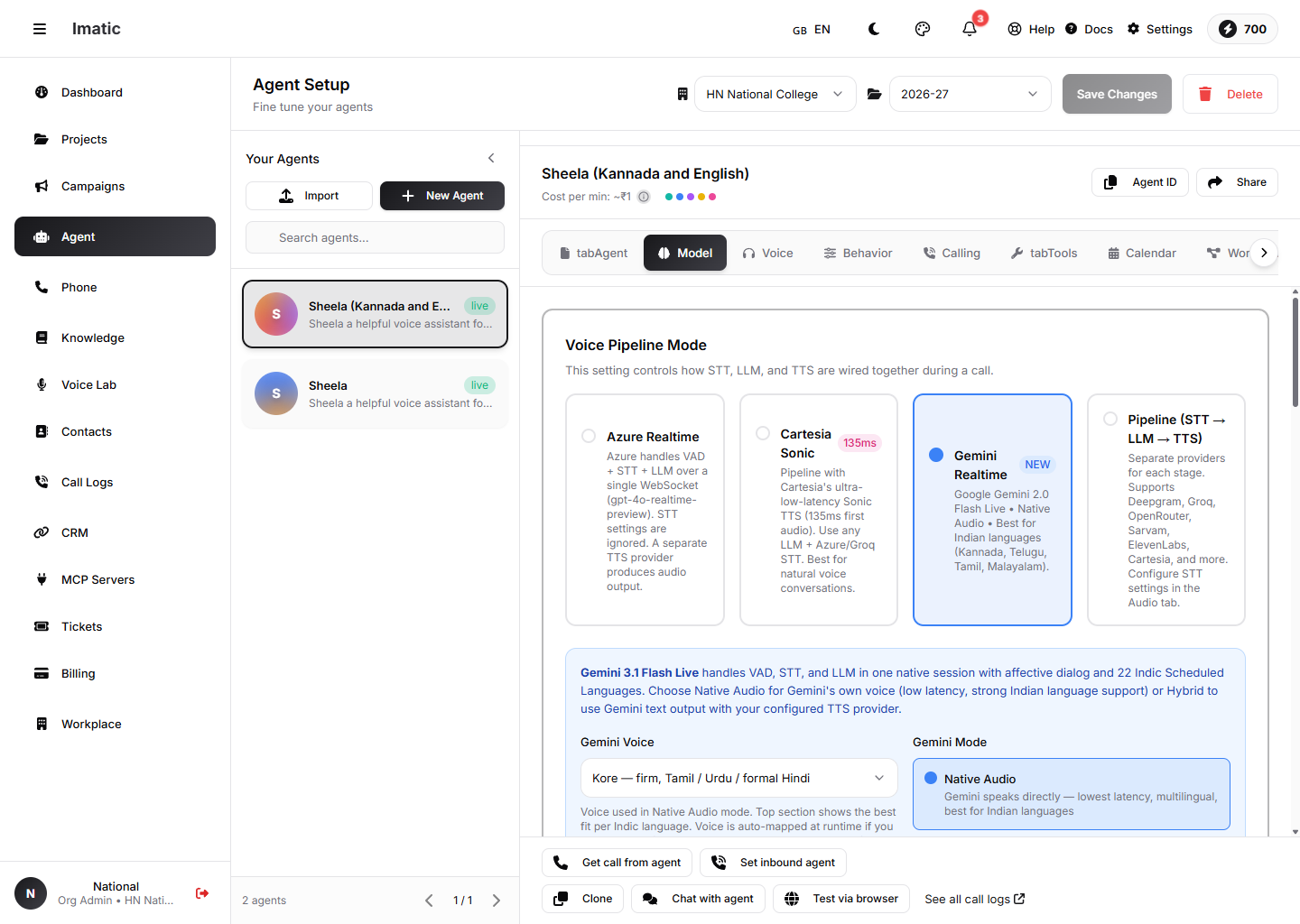 Model ٹیب: ایک Voice Pipeline موڈ منتخب کریں — Azure Realtime، Cartesia Sonic، Gemini Realtime، یا ایک علیحدہ STT→LLM→TTS Pipeline۔
Model ٹیب: ایک Voice Pipeline موڈ منتخب کریں — Azure Realtime، Cartesia Sonic، Gemini Realtime، یا ایک علیحدہ STT→LLM→TTS Pipeline۔
یہ ٹیب کی سب سے اہم ترتیب ہے — یہ کنٹرول کرتی ہے کہ کال کے دوران STT، LLM اور TTS کس طرح ایک ساتھ جڑے ہوتے ہیں۔ چار موڈز میں سے ایک منتخب کریں:
- Azure Realtime (طے شدہ) — Azure ایک واحد WebSocket پر ایک
gpt-4o-realtime-previewڈیپلائمنٹ کا استعمال کرتے ہوئے وائس-ایکٹیویٹی ڈیٹیکشن، speech-to-text اور LLM کو سنبھالتا ہے۔ Audio ٹیب پر STT ترتیبات کو نظر انداز کر دیا جاتا ہے؛ ایک علیحدہ TTS فراہم کنندہ آڈیو تیار کرتا ہے۔ - Cartesia Sonic — ایک پائپ لائن جو Cartesia کے انتہائی کم لیٹینسی والے Sonic TTS کا استعمال کرتی ہے، کسی بھی LLM اور ایک Azure/Groq STT کے ساتھ۔
- Gemini Realtime — Google Gemini Live بنیادی طور پر VAD، STT اور LLM کو سنبھالتا ہے، ہندوستانی زبانوں کے لیے مضبوط سپورٹ کے ساتھ۔ یہ اپنی آواز کے ساتھ بول سکتا ہے (Native Audio) یا آپ کے ترتیب کردہ TTS کے لیے متن نکال سکتا ہے (Hybrid)۔
- Pipeline (STT → LLM → TTS) — ہر مرحلے کے لیے علیحدہ فراہم کنندگان، جو آزادانہ طور پر ترتیب دیے گئے ہیں۔ اسے اس وقت استعمال کریں جب آپ ٹرانسکرائبر، ماڈل اور آواز پر مکمل کنٹرول چاہتے ہوں۔
ہر ریئل ٹائم موڈ کو ماڈلز کے ایک مخصوص خاندان کی ضرورت ہوتی ہے، اور ماڈل سیدھے ریئل ٹائم فراہم کنندہ کو بھیجا جاتا ہے — ایک غیر موافق قدر کال کے وقت ناکام ہو جاتی ہے۔ جب آپ موڈز سوئچ کرتے ہیں تو بلڈر خودکار طور پر ایک موافق ماڈل سیٹ کرتا ہے، اور محفوظ کرنے پر یہ ماڈل کو موڈ کے ساتھ ہم آہنگ کر دیتا ہے۔ خاص طور پر، gpt-4 جیسا ایک سادہ چیٹ ماڈل طے شدہ Azure Realtime موڈ کے لیے درست نہیں ہے اور محفوظ کرنے پر دوبارہ لکھ دیا جاتا ہے؛ ریئل ٹائم موڈز کے لیے ایک ریئل ٹائم ڈیپلائمنٹ منتخب کریں، اور Pipeline / Cartesia Sonic کے لیے ایک چیٹ-کمپلیشن ماڈل۔
فراہم کنندہ اور ماڈل منتخب کریں
مکمل طور پر منظم ریئل ٹائم موڈز کے علاوہ، آپ LLM فراہم کنندہ منتخب کرتے ہیں اور پھر اس فراہم کنندہ کے لیے ایک ماڈل۔ فراہم کنندگان کی فہرست صرف وہی فراہم کنندگان دکھاتی ہے جن کی اسناد آپ کی تنظیم نے فعال کر رکھی ہیں (Settings میں ترتیب دیے گئے)۔ جو فعال ہے اس پر منحصر، اس میں دیگر کے علاوہ Azure OpenAI، Google Gemini، Groq، OpenRouter اور Sarvam شامل ہو سکتے ہیں۔
- Azure کے لیے، ماڈل کے اختیارات آپ کے ترتیب دیے گئے ڈیپلائمنٹس سے آتے ہیں (ہر سند ایک ڈیپلائمنٹ ہے)۔
- واحد-کلید فراہم کنندگان کے لیے، ماڈل کی فہرست پلیٹ فارم کے ماڈل کیٹلاگ سے آتی ہے۔
وہ ماڈل منتخب کریں جو کام کے مطابق ہو: زیادہ صلاحیت والے ماڈلز پیچیدہ کالوں پر بہتر استدلال کرتے ہیں، جبکہ ہلکے ماڈلز تیزی سے جواب دیتے ہیں اور فی کال کم لاگت آتے ہیں۔ زیادہ تر کالنگ ایجنٹس کے لیے، لیٹینسی اتنی ہی اہمیت رکھتی ہے جتنی خام معیار۔
ماڈل پیرامیٹرز
Model Parameters سیکشن جنریشن کو کنٹرول کرتا ہے:
- Tokens — یہ حد مقرر کرتا ہے کہ ماڈل فی باری کتنا تیار کرتا ہے۔ اسے معتدل رکھیں تاکہ ایجنٹ فون کال پر بک بک نہ کرے۔
- Temperature — جوابات کتنے مختلف ہیں۔ سکرپٹ شدہ، تعمیل-حساس کالوں کے لیے کم؛ گفتگو والی آؤٹ ریچ کے لیے زیادہ۔
- Top P — نیوکلیئس-سیمپلنگ کٹ آف، تنوع کو کنٹرول کرنے کا ایک متبادل طریقہ۔
- Frequency penalty اور presence penalty — تکرار کی حوصلہ شکنی کرتے ہیں اور ماڈل کو نئے موضوعات متعارف کرانے کی ترغیب دیتے ہیں۔
اعلیٰ ترتیبات
Advanced Settings سیکشن آپریشنل کنٹرولز شامل کرتا ہے:
- Timeout (ms) — کسی باری پر ہار ماننے سے پہلے ماڈل کے لیے کتنا انتظار کرنا ہے۔
- Retry count اور retry delay (ms) — ایجنٹ کسی ناکام درخواست کو کیسے دوبارہ کوشش کرتا ہے۔
- Response format — Text یا JSON۔
- Stream enabled — ٹوکنز کو جیسے جیسے وہ تیار ہوتے ہیں سٹریم کریں (طے شدہ طور پر آن) تاکہ محسوس ہونے والی لیٹینسی کم ہو۔
- JSON mode — منظم JSON آؤٹ پٹ پر مجبور کریں۔
- Cost tracking — اس ایجنٹ کے لیے ٹوکن خرچ ریکارڈ کریں۔
آپ Custom Parameters کے تحت خام JSON کے طور پر اضافی فراہم کنندہ پیرامیٹرز بھی فراہم کر سکتے ہیں۔
فال بیک ماڈل
ایک فال بیک فراہم کنندہ اور ماڈل سیٹ کریں تاکہ اگر بنیادی دستیاب نہ ہو تو کالیں چلتی رہیں۔ اگر بنیادی جواب نہیں دے سکتا، تو ایجنٹ گفتگو ختم کرنے کے بجائے فال بیک کا استعمال کرتا ہے — کسی ایجنٹ کو لچکدار بنانے کا سب سے سادہ طریقہ۔
نالج بیس اور RAG
ریٹریول-اگمنٹڈ جنریشن یہاں، LLM ٹیب پر، Add Knowledge Base سیکشن میں ترتیب دی جاتی ہے۔ RAG Enabled کو آن کریں، ایک یا زیادہ نالج بیسز منتخب کریں، اور RAG Top K (کتنے اقتباسات بازیافت کرنے ہیں) اور similarity threshold (ایک اقتباس کو کتنا قریب سے میچ کرنا چاہیے) کو ٹیون کریں۔ ان کو ٹیون کرنے اور پہلے ایک نالج بیس بنانے کے لیے دیکھیں Knowledge & RAG۔
استعمال اور لاگت کا سراغ لگانا
ماڈل کا استعمال آپ کی تنظیم کے پری پیڈ بیلنس سے کریڈٹ استعمال کرتا ہے۔ اپنے ایجنٹس میں استعمال اور خرچ دیکھنے کے لیے بلنگ استعمال کریں — Overview پلان اور استعمال دکھاتا ہے، اور Wallet آپ کا پری پیڈ کریڈٹ، ٹاپ-اپس اور تاریخ دکھاتا ہے۔ مؤثر ماڈلز اور معقول ٹوکن کی حدود کا انتخاب لاگت کو کنٹرول کرنے کا سب سے براہِ راست طریقہ ہے۔