மொழி மாதிரி (LLM)
LLM தாவல், உங்கள் முகவர் எவ்வாறு சிந்திக்கிறது மற்றும் அதன் குரல் பைப்லைன் எவ்வாறு இணைக்கப்பட்டுள்ளது என்பதைத் தீர்மானிக்கிறது. இது குரல் பைப்லைன் முறையை (பேச்சு-உரை, மொழி மாதிரி மற்றும் உரை-பேச்சு எவ்வாறு ஒன்றாகப் பொருந்துகின்றன என்பது), எந்த LLM வழங்குநரும் மாதிரியும் உரையாடலை இயக்குகின்றன என்பது, உருவாக்க அளவுருக்கள், ஒரு பின்வாங்கல் மாதிரி, மற்றும் RAG / அறிவுத் தள இணைப்பு ஆகியவற்றைக் கட்டுப்படுத்துகிறது. /agent/setup-இல் உள்ள முகவர் உருவாக்கியில் இதை அமைக்கவும்.
குரல் பைப்லைன் முறை
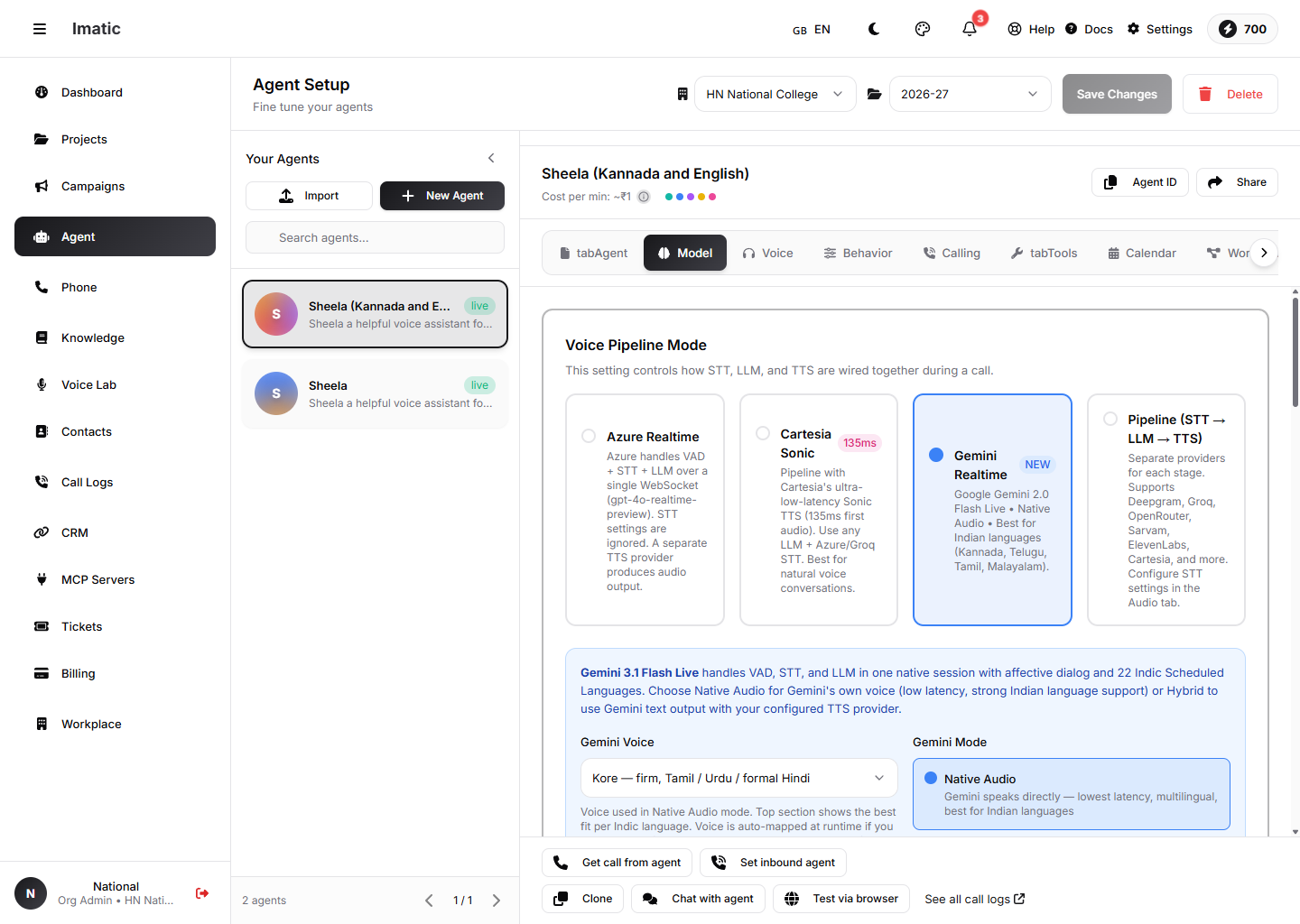 Model தாவல்: ஒரு Voice Pipeline Mode-ஐத் தேர்வுசெய்யவும் — Azure Realtime, Cartesia Sonic, Gemini Realtime, அல்லது தனித்தனி STT→LLM→TTS Pipeline.
Model தாவல்: ஒரு Voice Pipeline Mode-ஐத் தேர்வுசெய்யவும் — Azure Realtime, Cartesia Sonic, Gemini Realtime, அல்லது தனித்தனி STT→LLM→TTS Pipeline.
இது தாவலில் உள்ள மிக முக்கியமான அமைப்பு — ஒரு அழைப்பின்போது STT, LLM மற்றும் TTS எவ்வாறு ஒன்றாக இணைக்கப்படுகின்றன என்பதை இது கட்டுப்படுத்துகிறது. நான்கு முறைகளில் ஒன்றைத் தேர்வு செய்யுங்கள்:
- Azure Realtime (இயல்புநிலை) — ஒரு
gpt-4o-realtime-previewடெப்ளாய்மென்ட்டைப் பயன்படுத்தி, ஒரே WebSocket மீது குரல்-செயல்பாட்டு கண்டறிதல், பேச்சு-உரை மற்றும் LLM ஆகியவற்றை Azure கையாளுகிறது. ஆடியோ தாவலில் உள்ள STT அமைப்புகள் புறக்கணிக்கப்படுகின்றன; ஒரு தனி TTS வழங்குநர் ஆடியோவை உருவாக்குகிறது. - Cartesia Sonic — Cartesia-வின் மிகக்-குறைந்த-தாமத Sonic TTS-ஐப் பயன்படுத்தும் ஒரு பைப்லைன், எந்த LLM உடனும் மற்றும் ஒரு Azure/Groq STT உடனும்.
- Gemini Realtime — Google Gemini Live, VAD, STT மற்றும் LLM ஆகியவற்றை இயல்பாகவே கையாளுகிறது, இந்திய மொழிகளுக்கு வலுவான ஆதரவுடன். அது அதன் சொந்தக் குரலில் பேச முடியும் (Native Audio) அல்லது நீங்கள் கட்டமைத்த TTS-க்காக உரையை வெளியிட முடியும் (Hybrid).
- Pipeline (STT → LLM → TTS) — ஒவ்வொரு கட்டத்திற்கும் தனித்தனி வழங்குநர்கள், சுயாதீனமாகக் கட்டமைக்கப்படுகின்றன. டிரான்ஸ்கிரைபர், மாதிரி மற்றும் குரல் மீது முழுக் கட்டுப்பாடு வேண்டும் என்று நீங்கள் விரும்பும்போது இதைப் பயன்படுத்துங்கள்.
ஒவ்வொரு realtime முறைக்கும் ஒரு குறிப்பிட்ட மாதிரிக் குடும்பம் தேவை, மேலும் மாதிரி நேரடியாக realtime வழங்குநருக்கு அனுப்பப்படுகிறது — பொருந்தாத ஒரு மதிப்பு அழைப்பு நேரத்தில் தோல்வியடைகிறது. நீங்கள் முறைகளை மாற்றும்போது உருவாக்கி தானாகவே பொருந்தும் ஒரு மாதிரியை அமைக்கிறது, மேலும் சேமிப்பின்போது மாதிரியை முறைக்கு ஏற்ப சீரமைக்கிறது. குறிப்பாக, gpt-4 போன்ற ஒரு சாதாரண அரட்டை மாதிரி இயல்புநிலை Azure Realtime முறைக்கு செல்லுபடியாகாது மற்றும் சேமிப்பின்போது மறு-எழுதப்படுகிறது; realtime முறைகளுக்கு ஒரு realtime டெப்ளாய்மென்ட்டையும், Pipeline / Cartesia Sonic-க்கு ஒரு அரட்டை-நிறைவு மாதிரியையும் தேர்வு செய்யுங்கள்.
வழங்குநரையும் மாதிரியையும் தேர்வு செய்யுங்கள்
முழுமையாக-நிர்வகிக்கப்படும் realtime முறைகளுக்கு வெளியே, நீங்கள் LLM வழங்குநரையும் பின்னர் அந்த வழங்குநருக்கு ஒரு மாதிரியையும் தேர்வு செய்கிறீர்கள். உங்கள் நிறுவனம் கிரெடென்ஷியல்களை இயக்கியுள்ள வழங்குநர்களை மட்டுமே வழங்குநர் பட்டியல் காட்டுகிறது (அமைப்புகளில் கட்டமைக்கப்பட்டது). எது இயக்கப்பட்டுள்ளது என்பதைப் பொறுத்து, அதில் Azure OpenAI, Google Gemini, Groq, OpenRouter மற்றும் Sarvam அடங்கலாம்.
- Azure-க்கு, மாதிரி விருப்பங்கள் நீங்கள் கட்டமைத்த டெப்ளாய்மென்ட்களிலிருந்து வருகின்றன (ஒவ்வொரு கிரெடென்ஷியலும் ஒரு டெப்ளாய்மென்ட்).
- ஒற்றை-கீ வழங்குநர்களுக்கு, மாதிரிப் பட்டியல் தளத்தின் மாதிரி அட்டவணையிலிருந்து வருகிறது.
வேலைக்குப் பொருந்தும் மாதிரியைத் தேர்வு செய்யுங்கள்: அதிக-திறன் கொண்ட மாதிரிகள் சிக்கலான அழைப்புகளில் சிறப்பாகப் பகுத்தறிகின்றன, அதே நேரத்தில் இலகுவான மாதிரிகள் வேகமாகப் பதிலளித்து ஒவ்வொரு அழைப்பிற்கும் குறைவாகச் செலவாகின்றன. பெரும்பாலான அழைப்பு முகவர்களுக்கு, தூய தரத்தைப் போலவே தாமதமும் முக்கியம்.
மாதிரி அளவுருக்கள்
Model Parameters பகுதி உருவாக்கத்தைக் கட்டுப்படுத்துகிறது:
- Tokens — ஒவ்வொரு முறையிலும் மாதிரி எவ்வளவு உருவாக்குகிறது என்பதை வரம்பிடுகிறது. ஒரு தொலைபேசி அழைப்பில் முகவர் உளறாதவாறு இதை மிதமாக வைத்திருங்கள்.
- Temperature — பதில்கள் எவ்வளவு வேறுபட்டவை. ஸ்கிரிப்ட் செய்யப்பட்ட, இணக்க-உணர்திறன் கொண்ட அழைப்புகளுக்கு குறைவாக; உரையாடல் தொடர்புக்கு அதிகமாக.
- Top P — நியூக்ளியஸ்-மாதிரியாக்க வெட்டுப்புள்ளி, வேறுபாட்டைக் கட்டுப்படுத்த ஒரு மாற்று வழி.
- Frequency penalty மற்றும் presence penalty — மீண்டும் செய்வதை ஊக்கப்படுத்தாமல், புதிய தலைப்புகளை அறிமுகப்படுத்த மாதிரியை ஊக்குவிக்கின்றன.
மேம்பட்ட அமைப்புகள்
Advanced Settings பகுதி செயல்பாட்டுக் கட்டுப்பாடுகளைச் சேர்க்கிறது:
- Timeout (ms) — ஒரு முறையை விட்டுவிடுவதற்கு முன் மாதிரிக்காக எவ்வளவு நேரம் காத்திருக்க வேண்டும்.
- Retry count மற்றும் retry delay (ms) — தோல்வியடைந்த ஒரு கோரிக்கையை முகவர் எவ்வாறு மீண்டும் முயற்சிக்கிறது.
- Response format — Text அல்லது JSON.
- Stream enabled — குறைந்த உணரப்படும் தாமதத்திற்காக டோக்கன்கள் உருவாக்கப்படும்போதே அவற்றை ஸ்ட்ரீம் செய்யவும் (இயல்பாக இயக்கப்பட்டுள்ளது).
- JSON mode — கட்டமைக்கப்பட்ட JSON வெளியீட்டைக் கட்டாயப்படுத்துகிறது.
- Cost tracking — இந்த முகவருக்கான டோக்கன் செலவைப் பதிவு செய்கிறது.
Custom Parameters கீழ் கூடுதல வழங்குநர் அளவுருக்களை மூல JSON ஆகவும் நீங்கள் வழங்கலாம்.
பின்வாங்கல் மாதிரி
முதன்மை மாதிரி கிடைக்காவிட்டாலும் அழைப்புகள் தொடர்ந்து செயல்படும்படி ஒரு பின்வாங்கல் வழங்குநரையும் மாதிரியையும் அமைக்கவும். முதன்மையால் பதிலளிக்க முடியாவிட்டால், உரையாடலை விட்டுவிடாமல் முகவர் அதற்குப் பதிலாகப் பின்வாங்கலைப் பயன்படுத்துகிறது — ஒரு முகவரை மீள்திறன் கொண்டதாக்குவதற்கான மிக எளிய வழி.
அறிவுத் தளம் & RAG
மீட்டெடுப்பு-மேம்படுத்தப்பட்ட உருவாக்கம் (RAG) இங்கே, LLM தாவலில், Add Knowledge Base பகுதியில் கட்டமைக்கப்படுகிறது. RAG Enabled-ஐ இயக்கி, ஒன்று அல்லது அதற்கு மேற்பட்ட அறிவுத் தளங்களைத் தேர்ந்தெடுத்து, RAG Top K (எத்தனை பத்திகளை மீட்டெடுக்க வேண்டும்) மற்றும் ஒற்றுமை வரம்பு (ஒரு பத்தி எவ்வளவு நெருக்கமாகப் பொருந்த வேண்டும்) ஆகியவற்றை சரிசெய்யுங்கள். இவற்றை எவ்வாறு சரிசெய்வது மற்றும் முதலில் ஒரு அறிவுத் தளத்தை எவ்வாறு உருவாக்குவது என்பதற்கு அறிவு & RAG பார்க்கவும்.
பயன்பாடு மற்றும் செலவைக் கண்காணித்தல்
மாதிரிப் பயன்பாடு உங்கள் நிறுவனத்தின் முன்பணம் செலுத்திய இருப்பிலிருந்து கிரெடிட்களை செலவழிக்கிறது. உங்கள் முகவர்கள் முழுவதும் நுகர்வையும் செலவையும் காண, பில்லிங் பயன்படுத்தவும் — மேலோட்டம் திட்டத்தையும் பயன்பாட்டையும் காட்டுகிறது, மேலும் வாலட் உங்கள் முன்பணம் செலுத்திய கிரெடிட், டாப்-அப்கள் மற்றும் வரலாற்றைக் காட்டுகிறது. திறமையான மாதிரிகளையும் நியாயமான டோக்கன் வரம்புகளையும் தேர்வு செய்வது செலவைக் கட்டுப்படுத்துவதற்கான மிகவும் நேரடியான வழி.