ਭਾਸ਼ਾ ਮਾਡਲ (LLM)
LLM ਟੈਬ ਤੈਅ ਕਰਦਾ ਹੈ ਕਿ ਤੁਹਾਡਾ ਏਜੰਟ ਕਿਵੇਂ ਸੋਚਦਾ ਹੈ ਅਤੇ ਇਸ ਦੀ ਵੌਇਸ ਪਾਈਪਲਾਈਨ ਕਿਵੇਂ ਜੋੜੀ ਗਈ ਹੈ। ਇਹ ਵੌਇਸ ਪਾਈਪਲਾਈਨ ਮੋਡ (ਸਪੀਚ-ਟੂ-ਟੈਕਸਟ, ਭਾਸ਼ਾ ਮਾਡਲ ਅਤੇ ਟੈਕਸਟ-ਟੂ-ਸਪੀਚ ਕਿਵੇਂ ਇਕੱਠੇ ਫ਼ਿੱਟ ਹੁੰਦੇ ਹਨ), ਕਿਹੜਾ LLM ਪ੍ਰੋਵਾਈਡਰ ਅਤੇ ਮਾਡਲ ਗੱਲਬਾਤ ਨੂੰ ਚਲਾਉਂਦੇ ਹਨ, ਜਨਰੇਸ਼ਨ ਪੈਰਾਮੀਟਰ, ਇੱਕ ਫ਼ਾਲਬੈਕ ਮਾਡਲ, ਅਤੇ RAG / knowledge-base ਲਿੰਕੇਜ ਨੂੰ ਨਿਯੰਤਰਿਤ ਕਰਦਾ ਹੈ। ਇਸ ਨੂੰ /agent/setup 'ਤੇ ਏਜੰਟ ਬਿਲਡਰ ਵਿੱਚ ਸੈੱਟ ਕਰੋ।
ਵੌਇਸ ਪਾਈਪਲਾਈਨ ਮੋਡ
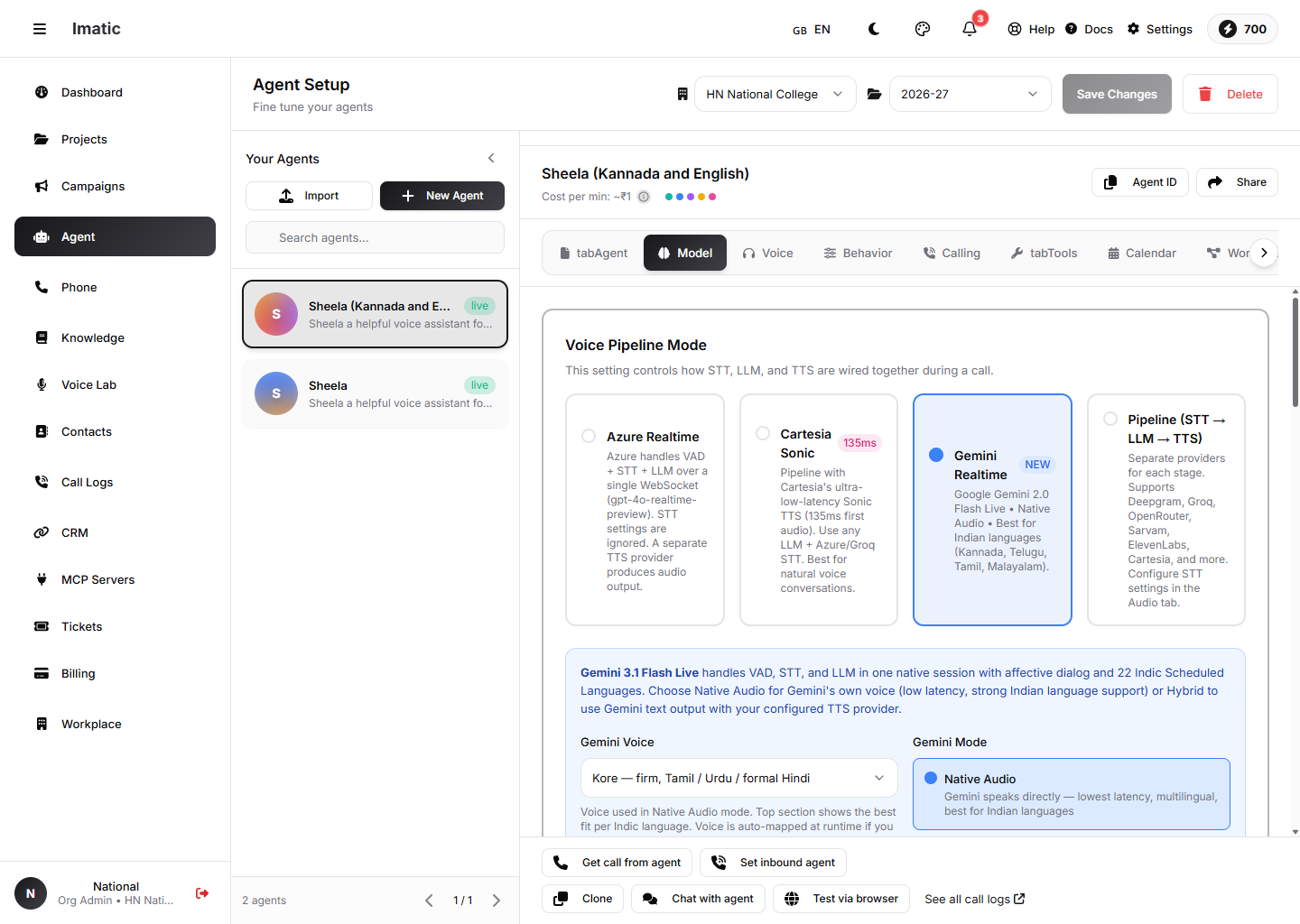 Model ਟੈਬ: ਇੱਕ Voice Pipeline Mode ਚੁਣੋ — Azure Realtime, Cartesia Sonic, Gemini Realtime, ਜਾਂ ਇੱਕ ਵੱਖਰੀ STT→LLM→TTS Pipeline।
Model ਟੈਬ: ਇੱਕ Voice Pipeline Mode ਚੁਣੋ — Azure Realtime, Cartesia Sonic, Gemini Realtime, ਜਾਂ ਇੱਕ ਵੱਖਰੀ STT→LLM→TTS Pipeline।
ਇਹ ਟੈਬ ਦੀ ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ ਸੈਟਿੰਗ ਹੈ — ਇਹ ਨਿਯੰਤਰਿਤ ਕਰਦੀ ਹੈ ਕਿ ਕਾਲ ਦੌਰਾਨ STT, LLM ਅਤੇ TTS ਕਿਵੇਂ ਇਕੱਠੇ ਜੋੜੇ ਜਾਂਦੇ ਹਨ। ਚਾਰ ਮੋਡਾਂ ਵਿੱਚੋਂ ਇੱਕ ਚੁਣੋ:
- Azure Realtime (ਮੂਲ) — Azure ਇੱਕ
gpt-4o-realtime-previewਡਿਪਲੌਇਮੈਂਟ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋਏ ਇੱਕ ਇਕੱਲੇ WebSocket ਉੱਤੇ ਵੌਇਸ-ਐਕਟੀਵਿਟੀ ਡਿਟੈਕਸ਼ਨ, ਸਪੀਚ-ਟੂ-ਟੈਕਸਟ ਅਤੇ LLM ਨੂੰ ਸੰਭਾਲਦਾ ਹੈ। Audio ਟੈਬ 'ਤੇ STT ਸੈਟਿੰਗਜ਼ ਨਜ਼ਰਅੰਦਾਜ਼ ਕੀਤੀਆਂ ਜਾਂਦੀਆਂ ਹਨ; ਇੱਕ ਵੱਖਰਾ TTS ਪ੍ਰੋਵਾਈਡਰ ਆਡੀਓ ਪੈਦਾ ਕਰਦਾ ਹੈ। - Cartesia Sonic — ਇੱਕ ਪਾਈਪਲਾਈਨ ਜੋ Cartesia ਦੀ ਅਤਿ-ਘੱਟ-ਲੇਟੈਂਸੀ ਵਾਲੀ Sonic TTS ਵਰਤਦੀ ਹੈ, ਕਿਸੇ ਵੀ LLM ਅਤੇ ਇੱਕ Azure/Groq STT ਨਾਲ।
- Gemini Realtime — Google Gemini Live ਮੂਲ ਤੌਰ 'ਤੇ VAD, STT ਅਤੇ LLM ਨੂੰ ਸੰਭਾਲਦਾ ਹੈ, ਭਾਰਤੀ ਭਾਸ਼ਾਵਾਂ ਲਈ ਮਜ਼ਬੂਤ ਸਮਰਥਨ ਨਾਲ। ਇਹ ਆਪਣੀ ਅਵਾਜ਼ ਨਾਲ ਬੋਲ ਸਕਦਾ ਹੈ (Native Audio) ਜਾਂ ਤੁਹਾਡੇ ਕਨਫ਼ਿਗਰ ਕੀਤੇ TTS ਲਈ ਟੈਕਸਟ ਆਊਟਪੁੱਟ ਕਰ ਸਕਦਾ ਹੈ (Hybrid)।
- Pipeline (STT → LLM → TTS) — ਹਰ ਪੜਾਅ ਲਈ ਵੱਖਰੇ ਪ੍ਰੋਵਾਈਡਰ, ਸੁਤੰਤਰ ਤੌਰ 'ਤੇ ਕਨਫ਼ਿਗਰ ਕੀਤੇ। ਇਸ ਨੂੰ ਉਦੋਂ ਵਰਤੋ ਜਦੋਂ ਤੁਸੀਂ ਟ੍ਰਾਂਸਕ੍ਰਾਈਬਰ, ਮਾਡਲ ਅਤੇ ਅਵਾਜ਼ ਉੱਤੇ ਪੂਰਾ ਨਿਯੰਤਰਣ ਚਾਹੁੰਦੇ ਹੋ।
ਹਰ ਰੀਅਲਟਾਈਮ ਮੋਡ ਨੂੰ ਮਾਡਲਾਂ ਦੇ ਇੱਕ ਖ਼ਾਸ ਪਰਿਵਾਰ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ, ਅਤੇ ਮਾਡਲ ਸਿੱਧਾ ਰੀਅਲਟਾਈਮ ਪ੍ਰੋਵਾਈਡਰ ਨੂੰ ਪਾਸ ਕੀਤਾ ਜਾਂਦਾ ਹੈ — ਇੱਕ ਅਸੰਗਤ ਮੁੱਲ ਕਾਲ ਵੇਲੇ ਫ਼ੇਲ੍ਹ ਹੋ ਜਾਂਦਾ ਹੈ। ਜਦੋਂ ਤੁਸੀਂ ਮੋਡ ਬਦਲਦੇ ਹੋ ਤਾਂ ਬਿਲਡਰ ਆਪਣੇ-ਆਪ ਇੱਕ ਸੰਗਤ ਮਾਡਲ ਸੈੱਟ ਕਰ ਦਿੰਦਾ ਹੈ, ਅਤੇ ਸੇਵ 'ਤੇ ਇਹ ਮਾਡਲ ਨੂੰ ਮੋਡ ਨਾਲ ਮਿਲਾ ਦਿੰਦਾ ਹੈ। ਖ਼ਾਸ ਤੌਰ 'ਤੇ, gpt-4 ਵਰਗਾ ਇੱਕ ਸਾਦਾ ਚੈਟ ਮਾਡਲ ਮੂਲ Azure Realtime ਮੋਡ ਲਈ ਯੋਗ ਨਹੀਂ ਹੈ ਅਤੇ ਸੇਵ 'ਤੇ ਮੁੜ-ਲਿਖਿਆ ਜਾਂਦਾ ਹੈ; ਰੀਅਲਟਾਈਮ ਮੋਡਾਂ ਲਈ ਇੱਕ ਰੀਅਲਟਾਈਮ ਡਿਪਲੌਇਮੈਂਟ ਚੁਣੋ, ਅਤੇ Pipeline / Cartesia Sonic ਲਈ ਇੱਕ ਚੈਟ-ਕੰਪਲੀਸ਼ਨ ਮਾਡਲ।
ਪ੍ਰੋਵਾਈਡਰ ਅਤੇ ਮਾਡਲ ਚੁਣੋ
ਪੂਰੀ ਤਰ੍ਹਾਂ-ਪ੍ਰਬੰਧਿਤ ਰੀਅਲਟਾਈਮ ਮੋਡਾਂ ਤੋਂ ਬਾਹਰ, ਤੁਸੀਂ LLM ਪ੍ਰੋਵਾਈਡਰ ਚੁਣਦੇ ਹੋ ਅਤੇ ਫਿਰ ਉਸ ਪ੍ਰੋਵਾਈਡਰ ਲਈ ਇੱਕ ਮਾਡਲ। ਪ੍ਰੋਵਾਈਡਰ ਸੂਚੀ ਸਿਰਫ਼ ਉਹੀ ਪ੍ਰੋਵਾਈਡਰ ਦਿਖਾਉਂਦੀ ਹੈ ਜਿਨ੍ਹਾਂ ਲਈ ਤੁਹਾਡੀ ਸੰਸਥਾ ਨੇ ਕ੍ਰੈਡੈਂਸ਼ੀਅਲ ਚਾਲੂ ਕੀਤੇ ਹਨ (Settings ਵਿੱਚ ਕਨਫ਼ਿਗਰ ਕੀਤੇ)। ਜੋ ਚਾਲੂ ਹੈ ਉਸ ਅਨੁਸਾਰ, ਇਸ ਵਿੱਚ Azure OpenAI, Google Gemini, Groq, OpenRouter ਅਤੇ Sarvam ਸ਼ਾਮਲ ਹੋ ਸਕਦੇ ਹਨ।
- Azure ਲਈ, ਮਾਡਲ ਵਿਕਲਪ ਤੁਹਾਡੇ ਕਨਫ਼ਿਗਰ ਕੀਤੇ ਡਿਪਲੌਇਮੈਂਟਾਂ ਤੋਂ ਆਉਂਦੇ ਹਨ (ਹਰ ਕ੍ਰੈਡੈਂਸ਼ੀਅਲ ਇੱਕ ਡਿਪਲੌਇਮੈਂਟ ਹੈ)।
- ਇਕੱਲੀ-ਕੁੰਜੀ ਵਾਲੇ ਪ੍ਰੋਵਾਈਡਰਾਂ ਲਈ, ਮਾਡਲ ਸੂਚੀ ਪਲੇਟਫ਼ਾਰਮ ਦੇ ਮਾਡਲ ਕੈਟਾਲੌਗ ਤੋਂ ਆਉਂਦੀ ਹੈ।
ਉਹ ਮਾਡਲ ਚੁਣੋ ਜੋ ਕੰਮ ਨਾਲ ਫ਼ਿੱਟ ਬੈਠਦਾ ਹੈ: ਉੱਚ-ਸਮਰੱਥਾ ਵਾਲੇ ਮਾਡਲ ਜਟਿਲ ਕਾਲਾਂ 'ਤੇ ਬਿਹਤਰ ਤਰਕ ਕਰਦੇ ਹਨ, ਜਦਕਿ ਹਲਕੇ ਮਾਡਲ ਤੇਜ਼ ਜਵਾਬ ਦਿੰਦੇ ਹਨ ਅਤੇ ਪ੍ਰਤੀ ਕਾਲ ਘੱਟ ਖ਼ਰਚ ਕਰਦੇ ਹਨ। ਬਹੁਤੇ ਕਾਲਿੰਗ ਏਜੰਟਾਂ ਲਈ, ਲੇਟੈਂਸੀ ਉਨੀ ਹੀ ਮਾਅਨੇ ਰੱਖਦੀ ਹੈ ਜਿੰਨੀ ਕਿ ਨਿਰੀ ਗੁਣਵੱਤਾ।
ਮਾਡਲ ਪੈਰਾਮੀਟਰ
Model Parameters ਸੈਕਸ਼ਨ ਜਨਰੇਸ਼ਨ ਨੂੰ ਨਿਯੰਤਰਿਤ ਕਰਦਾ ਹੈ:
- Tokens — ਮਾਡਲ ਪ੍ਰਤੀ ਵਾਰੀ ਕਿੰਨਾ ਪੈਦਾ ਕਰਦਾ ਹੈ, ਇਸ 'ਤੇ ਸੀਮਾ ਲਾਉਂਦਾ ਹੈ। ਇਸ ਨੂੰ ਸੰਜਮ ਨਾਲ ਰੱਖੋ ਤਾਂ ਜੋ ਏਜੰਟ ਫ਼ੋਨ ਕਾਲ 'ਤੇ ਬਕਵਾਸ ਨਾ ਕਰੇ।
- Temperature — ਜਵਾਬ ਕਿੰਨੇ ਵੰਨ-ਸੁਵੰਨੇ ਹਨ। ਸਕ੍ਰਿਪਟ ਕੀਤੀਆਂ, ਅਨੁਪਾਲਨ-ਸੰਵੇਦਨਸ਼ੀਲ ਕਾਲਾਂ ਲਈ ਘੱਟ; ਗੱਲਬਾਤ-ਮੁਖੀ ਪਹੁੰਚ ਲਈ ਵੱਧ।
- Top P — ਨਿਊਕਲੀਅਸ-ਸੈਂਪਲਿੰਗ ਕੱਟਆਫ਼, ਵੰਨ-ਸੁਵੰਨਤਾ ਨਿਯੰਤਰਿਤ ਕਰਨ ਦਾ ਇੱਕ ਵਿਕਲਪਿਕ ਤਰੀਕਾ।
- Frequency penalty ਅਤੇ presence penalty — ਦੁਹਰਾਅ ਨੂੰ ਨਿਰਉਤਸ਼ਾਹਿਤ ਕਰਦੇ ਹਨ ਅਤੇ ਮਾਡਲ ਨੂੰ ਨਵੇਂ ਵਿਸ਼ੇ ਪੇਸ਼ ਕਰਨ ਲਈ ਉਤਸ਼ਾਹਿਤ ਕਰਦੇ ਹਨ।
ਉੱਨਤ ਸੈਟਿੰਗਜ਼
Advanced Settings ਸੈਕਸ਼ਨ ਪਰਿਚਾਲਨ ਨਿਯੰਤਰਣ ਜੋੜਦਾ ਹੈ:
- Timeout (ms) — ਇੱਕ ਵਾਰੀ ਛੱਡਣ ਤੋਂ ਪਹਿਲਾਂ ਮਾਡਲ ਲਈ ਕਿੰਨਾ ਚਿਰ ਉਡੀਕ ਕਰਨੀ ਹੈ।
- Retry count ਅਤੇ retry delay (ms) — ਏਜੰਟ ਇੱਕ ਫ਼ੇਲ੍ਹ ਹੋਈ ਬੇਨਤੀ ਨੂੰ ਕਿਵੇਂ ਮੁੜ-ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ।
- Response format — Text ਜਾਂ JSON।
- Stream enabled — ਟੋਕਨ ਪੈਦਾ ਹੁੰਦੇ ਹੀ ਸਟ੍ਰੀਮ ਕਰੋ (ਮੂਲ ਤੌਰ 'ਤੇ ਚਾਲੂ) ਤਾਂ ਜੋ ਮਹਿਸੂਸ ਹੋਣ ਵਾਲੀ ਲੇਟੈਂਸੀ ਘੱਟ ਰਹੇ।
- JSON mode — ਢਾਂਚਾਗਤ JSON ਆਊਟਪੁੱਟ ਨੂੰ ਮਜਬੂਰ ਕਰੋ।
- Cost tracking — ਇਸ ਏਜੰਟ ਲਈ ਟੋਕਨ ਖ਼ਰਚ ਰਿਕਾਰਡ ਕਰੋ।
ਤੁਸੀਂ Custom Parameters ਅਧੀਨ ਕੱਚੇ JSON ਵਜੋਂ ਵਾਧੂ ਪ੍ਰੋਵਾਈਡਰ ਪੈਰਾਮੀਟਰ ਵੀ ਮੁਹੱਈਆ ਕਰ ਸਕਦੇ ਹੋ।
ਫ਼ਾਲਬੈਕ ਮਾਡਲ
ਇੱਕ ਫ਼ਾਲਬੈਕ ਪ੍ਰੋਵਾਈਡਰ ਅਤੇ ਮਾਡਲ ਸੈੱਟ ਕਰੋ ਤਾਂ ਜੋ ਜੇ ਮੁੱਖ ਉਪਲਬਧ ਨਾ ਹੋਵੇ ਤਾਂ ਕਾਲਾਂ ਚੱਲਦੀਆਂ ਰਹਿਣ। ਜੇ ਮੁੱਖ ਜਵਾਬ ਨਹੀਂ ਦੇ ਸਕਦਾ, ਤਾਂ ਏਜੰਟ ਗੱਲਬਾਤ ਛੱਡਣ ਦੀ ਬਜਾਏ ਫ਼ਾਲਬੈਕ ਵਰਤਦਾ ਹੈ — ਏਜੰਟ ਨੂੰ ਲਚਕੀਲਾ ਬਣਾਉਣ ਦਾ ਸਭ ਤੋਂ ਸੌਖਾ ਤਰੀਕਾ।
ਗਿਆਨ-ਆਧਾਰ ਅਤੇ RAG
Retrieval-augmented generation ਇੱਥੇ, LLM ਟੈਬ 'ਤੇ, Add Knowledge Base ਸੈਕਸ਼ਨ ਵਿੱਚ ਕਨਫ਼ਿਗਰ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। RAG Enabled ਚਾਲੂ ਕਰੋ, ਇੱਕ ਜਾਂ ਵੱਧ ਗਿਆਨ-ਆਧਾਰ ਚੁਣੋ, ਅਤੇ RAG Top K (ਕਿੰਨੇ ਪੈਸੇਜ ਲਿਆਉਣੇ ਹਨ) ਅਤੇ similarity threshold (ਇੱਕ ਪੈਸੇਜ ਕਿੰਨਾ ਨੇੜਿਓਂ ਮੇਲ ਖਾਣਾ ਚਾਹੀਦਾ ਹੈ) ਟਿਊਨ ਕਰੋ। ਇਹਨਾਂ ਨੂੰ ਟਿਊਨ ਕਰਨ ਅਤੇ ਪਹਿਲਾਂ ਗਿਆਨ-ਆਧਾਰ ਕਿਵੇਂ ਬਣਾਉਣਾ ਹੈ, ਇਸ ਲਈ ਗਿਆਨ ਅਤੇ RAG ਵੇਖੋ।
ਵਰਤੋਂ ਅਤੇ ਲਾਗਤ ਨੂੰ ਟ੍ਰੈਕ ਕਰਨਾ
ਮਾਡਲ ਵਰਤੋਂ ਤੁਹਾਡੀ ਸੰਸਥਾ ਦੇ ਪ੍ਰੀਪੇਡ ਬੈਲੈਂਸ ਤੋਂ ਕ੍ਰੈਡਿਟ ਖਪਤ ਕਰਦੀ ਹੈ। ਆਪਣੇ ਏਜੰਟਾਂ ਵਿੱਚ ਖਪਤ ਅਤੇ ਖ਼ਰਚ ਵੇਖਣ ਲਈ, ਬਿਲਿੰਗ ਵਰਤੋ — Overview ਯੋਜਨਾ ਅਤੇ ਵਰਤੋਂ ਦਿਖਾਉਂਦਾ ਹੈ, ਅਤੇ Wallet ਤੁਹਾਡਾ ਪ੍ਰੀਪੇਡ ਕ੍ਰੈਡਿਟ, ਟਾਪ-ਅੱਪ ਅਤੇ ਇਤਿਹਾਸ ਦਿਖਾਉਂਦਾ ਹੈ। ਕੁਸ਼ਲ ਮਾਡਲ ਅਤੇ ਵਾਜਬ ਟੋਕਨ ਸੀਮਾਵਾਂ ਚੁਣਨਾ ਲਾਗਤ ਨਿਯੰਤਰਿਤ ਕਰਨ ਦਾ ਸਭ ਤੋਂ ਸਿੱਧਾ ਤਰੀਕਾ ਹੈ।