भाषा मॉडेल (LLM)
LLM टॅब तुमचा एजंट कसा विचार करतो आणि त्याची व्हॉइस पाइपलाइन कशी जोडलेली आहे ते ठरवतो. तो व्हॉइस पाइपलाइन मोड (speech-to-text, भाषा मॉडेल आणि text-to-speech एकत्र कसे बसतात), कोणते LLM प्रदाता आणि मॉडेल संभाषण चालवतात, निर्मिती पॅरामीटर, एक fallback मॉडेल, आणि RAG / ज्ञान-आधार जोडणी नियंत्रित करतो. हे एजंट बिल्डरमध्ये /agent/setup वर सेट करा.
व्हॉइस पाइपलाइन मोड
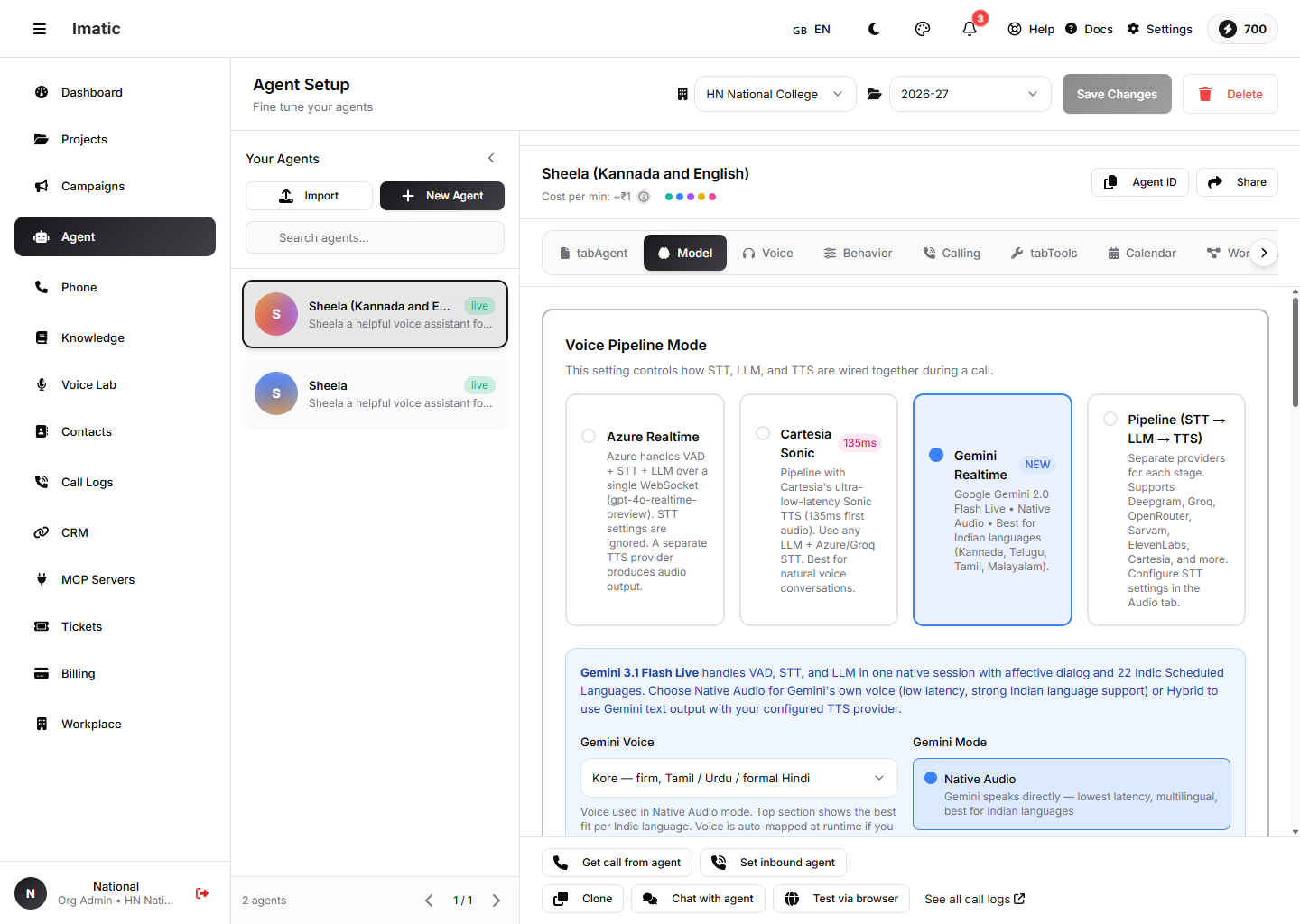 Model टॅब: एक Voice Pipeline Mode निवडा — Azure Realtime, Cartesia Sonic, Gemini Realtime, किंवा स्वतंत्र STT→LLM→TTS Pipeline.
Model टॅब: एक Voice Pipeline Mode निवडा — Azure Realtime, Cartesia Sonic, Gemini Realtime, किंवा स्वतंत्र STT→LLM→TTS Pipeline.
ही टॅबवरील सर्वात महत्त्वाची सेटिंग आहे — ती एका कॉल दरम्यान STT, LLM आणि TTS एकत्र कसे जोडले जातात ते नियंत्रित करते. चार मोडपैकी एक निवडा:
- Azure Realtime (डिफॉल्ट) — Azure एका
gpt-4o-realtime-previewडिप्लॉयमेंटचा वापर करून एका एकल WebSocket वर voice-activity detection, speech-to-text आणि LLM हाताळते. Audio टॅबवरील STT सेटिंग्ज दुर्लक्षित केल्या जातात; एक वेगळा TTS प्रदाता ऑडिओ तयार करतो. - Cartesia Sonic — एक पाइपलाइन जी Cartesia चे अति-कमी-latency Sonic TTS, कोणत्याही LLM आणि एका Azure/Groq STT सह वापरते.
- Gemini Realtime — Google Gemini Live VAD, STT आणि LLM नैसर्गिकरित्या हाताळते, भारतीय भाषांना मजबूत समर्थनासह. तो त्याच्या स्वतःच्या आवाजाने बोलू शकतो (Native Audio) किंवा तुमच्या कॉन्फिगर केलेल्या TTS साठी मजकूर आउटपुट करू शकतो (Hybrid).
- Pipeline (STT → LLM → TTS) — प्रत्येक टप्प्यासाठी वेगळे प्रदाते, स्वतंत्रपणे कॉन्फिगर केलेले. जेव्हा तुम्हाला ट्रान्सक्रायबर, मॉडेल आणि आवाजावर पूर्ण नियंत्रण हवे असेल तेव्हा हे वापरा.
प्रत्येक realtime मोडला एका विशिष्ट मॉडेल कुटुंबाची गरज असते, आणि मॉडेल थेट realtime प्रदात्याकडे दिले जाते — एक विसंगत मूल्य कॉलच्या वेळी अयशस्वी होते. जेव्हा तुम्ही मोड स्विच करता तेव्हा बिल्डर एक सुसंगत मॉडेल आपोआप सेट करतो, आणि जतनावर तो मॉडेल मोडशी जुळवतो. विशेषतः, gpt-4 सारखे एक साधे चॅट मॉडेल डिफॉल्ट Azure Realtime मोडसाठी वैध नाही आणि जतनावर पुन्हा लिहिले जाते; realtime मोडसाठी एक realtime डिप्लॉयमेंट निवडा, आणि Pipeline / Cartesia Sonic साठी एक chat-completion मॉडेल.
प्रदाता आणि मॉडेल निवडा
पूर्ण-व्यवस्थापित realtime मोडच्या बाहेर, तुम्ही LLM प्रदाता आणि मग त्या प्रदात्यासाठी एक मॉडेल निवडता. प्रदाता सूची फक्त तुमच्या संस्थेने ज्यांची क्रेडेन्शियल सक्षम केली आहेत (Settings मध्ये कॉन्फिगर केलेली) तेच प्रदाते दाखवते. काय सक्षम आहे यावर अवलंबून, त्यात इतरांसह Azure OpenAI, Google Gemini, Groq, OpenRouter आणि Sarvam यांचा समावेश असू शकतो.
- Azure साठी, मॉडेल पर्याय तुमच्या कॉन्फिगर केलेल्या डिप्लॉयमेंटमधून येतात (प्रत्येक क्रेडेन्शियल एक डिप्लॉयमेंट आहे).
- एकल-की प्रदात्यांसाठी, मॉडेल सूची प्लॅटफॉर्मच्या मॉडेल कॅटलॉगमधून येते.
कामाला बसणारे मॉडेल निवडा: उच्च-क्षमतेची मॉडेल जटिल कॉलवर अधिक चांगला तर्क करतात, तर हलकी मॉडेल जलद प्रतिसाद देतात आणि प्रति कॉल कमी खर्च करतात. बहुतेक कॉलिंग एजंटसाठी, latency कच्च्या गुणवत्तेइतकीच महत्त्वाची आहे.
मॉडेल पॅरामीटर
Model Parameters विभाग निर्मिती नियंत्रित करतो:
- Tokens — मॉडेल प्रति वळण किती तयार करते ते मर्यादित करते. हे माफक ठेवा जेणेकरून एजंट एका फोन कॉलवर बडबड करत नाही.
- Temperature — प्रत्युत्तरे किती वैविध्यपूर्ण आहेत. स्क्रिप्टेड, अनुपालन-संवेदनशील कॉलसाठी कमी; संभाषणात्मक संपर्कासाठी अधिक.
- Top P — nucleus-sampling कटऑफ, विविधता नियंत्रित करण्याचा एक पर्यायी मार्ग.
- Frequency penalty आणि presence penalty — पुनरावृत्ती परावृत्त करा आणि मॉडेलला नवीन विषय आणण्यास प्रोत्साहित करा.
प्रगत सेटिंग्ज
Advanced Settings विभाग कार्यात्मक नियंत्रणे जोडतो:
- Timeout (ms) — एका वळणावर हार मानण्यापूर्वी मॉडेलची किती वेळ प्रतीक्षा करायची.
- Retry count आणि retry delay (ms) — एजंट एका अयशस्वी विनंतीचा पुन्हा प्रयत्न कसा करतो.
- Response format — Text किंवा JSON.
- Stream enabled — टोकन तयार होताच स्ट्रीम करा (डिफॉल्टपणे चालू) कमी जाणवलेल्या latency साठी.
- JSON mode — संरचित JSON आउटपुट बळजबरीने करा.
- Cost tracking — या एजंटसाठी टोकन खर्च नोंदवा.
तुम्ही Custom Parameters अंतर्गत कच्चे JSON म्हणून अतिरिक्त प्रदाता पॅरामीटरही पुरवू शकता.
Fallback मॉडेल
एक fallback प्रदाता आणि मॉडेल सेट करा जेणेकरून प्राथमिक अनुपलब्ध असल्यास कॉल चालू राहतील. जर प्राथमिक प्रतिसाद देऊ शकत नसेल, तर एजंट संभाषण सोडण्याऐवजी fallback वापरतो — एजंट लवचिक बनवण्याचा सर्वात सोपा मार्ग.
ज्ञान आधार आणि RAG
Retrieval-augmented generation इथे, LLM टॅबवर, Add Knowledge Base विभागात कॉन्फिगर केले जाते. RAG Enabled चालू करा, एक किंवा अधिक ज्ञान आधार निवडा, आणि RAG Top K (किती उतारे पुनर्प्राप्त करायचे) आणि similarity threshold (एक उतारा किती जवळून जुळला पाहिजे) सुधारा. हे कसे सुधारायचे आणि प्रथम एक ज्ञान आधार कसा तयार करायचा यासाठी ज्ञान आणि RAG पहा.
वापर आणि खर्च ट्रॅक करणे
मॉडेल वापर तुमच्या संस्थेच्या प्रीपेड शिल्लकमधून क्रेडिट वापरतो. तुमच्या एजंटमध्ये वापर आणि खर्च पाहण्यासाठी, बिलिंग वापरा — Overview योजना आणि वापर दाखवते, आणि Wallet तुमचे प्रीपेड क्रेडिट, टॉप-अप आणि इतिहास दाखवते. कार्यक्षम मॉडेल आणि समजूतदार टोकन मर्यादा निवडणे हा खर्च नियंत्रित करण्याचा सर्वात थेट मार्ग आहे.