വോയ്സും ഓഡിയോയും (STT/TTS)
Audio ടാബ് നിങ്ങളുടെ ഏജന്റ് എങ്ങനെ കേൾക്കുകയും സംസാരിക്കുകയും ചെയ്യുന്നുവെന്ന് നിയന്ത്രിക്കുന്നു. speech-to-text (STT) ഉം text-to-speech (TTS) ഉം മൾട്ടി-പ്രൊവൈഡർ ആണ് — നിങ്ങൾ ഒരു പ്രൊവൈഡർ തിരഞ്ഞെടുക്കുന്നു, പിന്നെ ഒരു മോഡലും പ്രൊവൈഡർ-നിർദ്ദിഷ്ട നിയന്ത്രണങ്ങളും. ഇവ ശരിയാക്കുന്നതാണ് ഒരു ഏജന്റ് സ്വാഭാവികമായി കേൾക്കാനും കോളർമാരെ കൃത്യമായി മനസ്സിലാക്കാനും കാരണമാകുന്നത്. /agent/setup-ലെ ഏജന്റ് ബിൽഡറിൽ ഇത് സജ്ജമാക്കുക.
speech-to-text ക്രമീകരണങ്ങൾ Pipeline വോയ്സ് മോഡിലാണ് ബാധകമാകുന്നത്. റിയൽടൈം മോഡുകളിൽ (Azure Realtime, Gemini Realtime) ട്രാൻസ്ക്രിപ്ഷൻ പ്രൊവൈഡർ ആന്തരികമായി കൈകാര്യം ചെയ്യുന്നു, അതിനാൽ STT വിഭാഗം അവഗണിക്കപ്പെടുന്നു. വോയ്സ് പൈപ്പ്ലൈൻ മോഡ് LLM ടാബിൽ സജ്ജമാക്കുക.
Speech-to-text
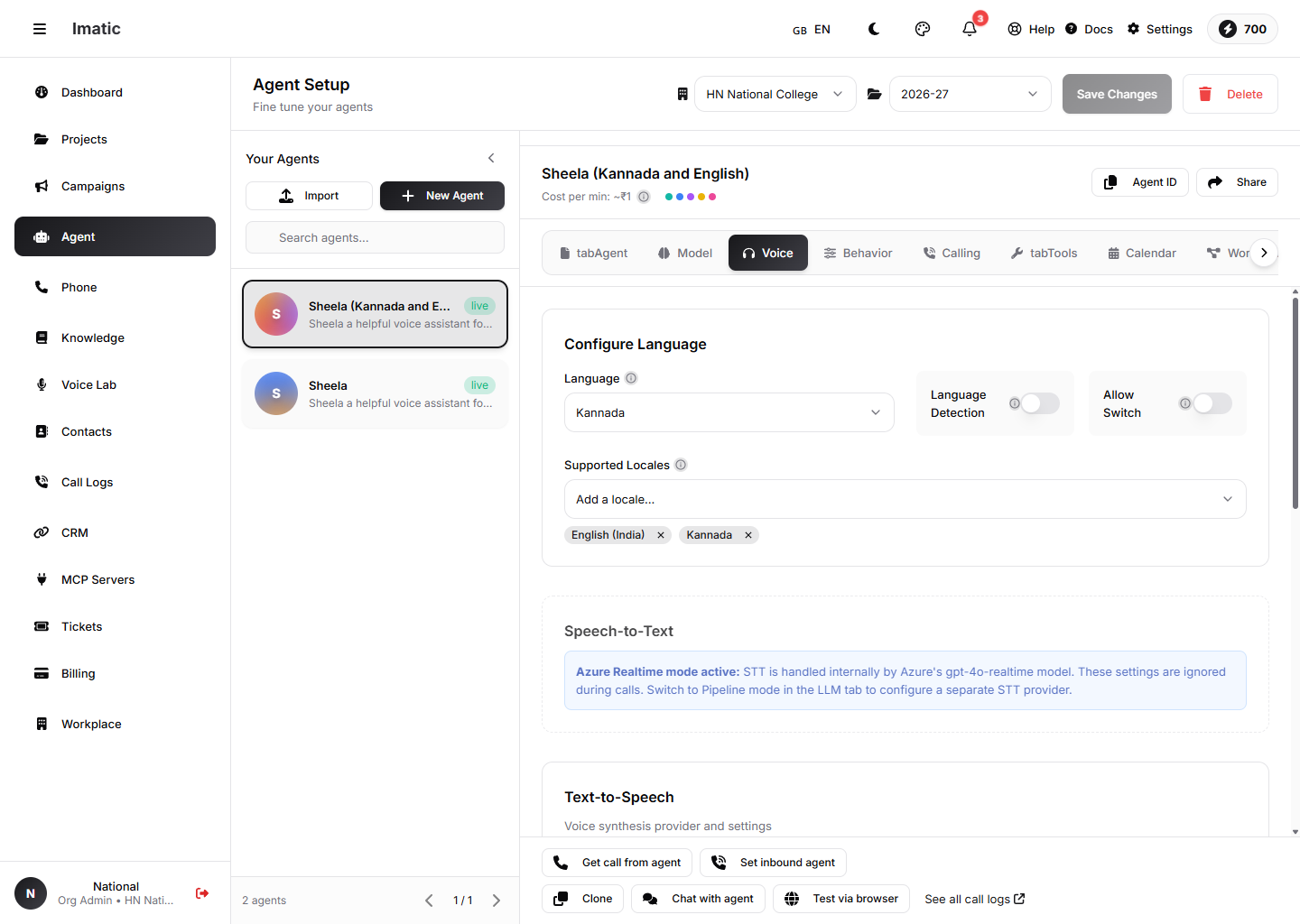 Voice ടാബ്: ഭാഷ, പിന്തുണയ്ക്കുന്ന ലൊക്കേലുകൾ, ഭാഷാ കണ്ടെത്തൽ, STT / TTS ദാതാവിന്റെ ക്രമീകരണങ്ങൾ.
Voice ടാബ്: ഭാഷ, പിന്തുണയ്ക്കുന്ന ലൊക്കേലുകൾ, ഭാഷാ കണ്ടെത്തൽ, STT / TTS ദാതാവിന്റെ ക്രമീകരണങ്ങൾ.
speech-to-text കോളറുടെ ഓഡിയോയെ ഏജന്റിന് പ്രവർത്തിക്കാൻ കഴിയുന്ന ടെക്സ്റ്റാക്കി മാറ്റുന്നു. നിങ്ങളുടെ കോളർമാർക്കും ഡൊമെയ്നിനും അനുയോജ്യമായ ഒരു പ്രൊവൈഡറും മോഡലും തിരഞ്ഞെടുക്കുക. STT പ്രൊവൈഡർമാർ ഇവയാണ്:
- Deepgram (ഡിഫോൾട്ട്) — Nova-3 / Nova-2 എന്നിവയും മറ്റും.
- Azure — Default, Conversation മോഡലുകൾ.
- Groq — Whisper Large v3 / Turbo.
- Sarvam — Saarika (ഇൻഡിക്).
പൊതുവായ നിയന്ത്രണങ്ങൾ
ഭാഷ, വിരാമചിഹ്നം, വാക്ക് ടൈംസ്റ്റാമ്പുകൾ, ഇടക്കാല ഫലങ്ങൾ എന്നിവ എല്ലാ പ്രൊവൈഡർമാർക്കും ബാധകമാണ്. ട്രാൻസ്ക്രിപ്ഷൻ കൃത്യതയിലെ ഏറ്റവും വലിയ ഒറ്റ ഘടകം ശരിയായ ഭാഷ സജ്ജമാക്കുന്നതാണ്.
പ്രൊവൈഡർ-നിർദ്ദിഷ്ട നിയന്ത്രണങ്ങൾ
ചില നിയന്ത്രണങ്ങൾ അവയെ പിന്തുണയ്ക്കുന്ന പ്രൊവൈഡറിന് മാത്രമേ ദൃശ്യമാകൂ:
- Deepgram — keyword boost, smart format, filler removal, diarization (ട്രാൻസ്ക്രിപ്റ്റിനെ സംസാരിക്കുന്നയാളനുസരിച്ച് വേർതിരിക്കുക), profanity filter, alternatives, latency mode.
- Azure — profanity mode (masked / removed / raw).
- Sarvam — code mixing.
തിരിച്ചറിയൽ മെച്ചപ്പെടുത്താൻ നിങ്ങൾക്ക് ഇഷ്ടാനുസൃത പദസമ്പത്തും (ഉൽപ്പന്ന പേരുകൾ, ബ്രാൻഡ് പദങ്ങൾ, പദപ്രയോഗങ്ങൾ) ചേർക്കാം, കൂടാതെ endpointing-ഉം VAD turnoff സമയങ്ങളും ട്യൂൺ ചെയ്യാം.
ട്രാൻസ്ക്രിപ്റ്റ് PII redaction (ഏതൊക്കെ സെൻസിറ്റീവ് തരങ്ങൾ മറയ്ക്കണം) ക്രമീകരിക്കുന്നത് ഇവിടെയല്ല, Guardrails ടാബിലാണ്. ഏജന്റുകൾ അവലോകനം കാണുക.
Text-to-speech
text-to-speech നിങ്ങളുടെ ഏജന്റ് സംസാരിക്കുന്ന വോയ്സാണ്. ഒരു പ്രൊവൈഡർ, മോഡൽ, വോയ്സ് എന്നിവ തിരഞ്ഞെടുക്കുക. TTS പ്രൊവൈഡർമാർ ഇവയാണ്:
- ElevenLabs (ഡിഫോൾട്ട്) — Turbo v2.5 / v2, Multilingual v2.
- Azure — Neural, Standard.
- Google — Gemini TTS.
- Cartesia — Sonic.
- Groq — Orpheus.
- Sarvam — Bulbul (ഇൻഡിക്).
വോയ്സ്
നിങ്ങളുടെ ബ്രാൻഡിനും കോളർമാർക്കും അനുയോജ്യമായ വോയ്സ് തിരഞ്ഞെടുക്കുക. Voice Lab-ൽ സൃഷ്ടിച്ച ഒരു ഇഷ്ടാനുസൃത വോയ്സും നിങ്ങൾക്ക് ഉപയോഗിക്കാം — ഒരു ചെറിയ സാമ്പിളിൽ നിന്ന് ഒരു വോയ്സ് ക്ലോൺ ചെയ്ത് ഏജന്റിന് നൽകുക. അത് കേൾക്കാൻ പ്രിവ്യൂ ബട്ടൺ ഉപയോഗിക്കുക.
പൊതുവായ നിയന്ത്രണങ്ങൾ
Speed, pitch, style, volume, emotion, emphasis, output format, ഇഷ്ടാനുസൃത ഉച്ചാരണങ്ങൾ എന്നിവ എല്ലാ പ്രൊവൈഡർമാർക്കും ബാധകമാണ്. അൽപ്പം പതുക്കെയുള്ള സംസാരം ഒരു ഫോൺ കോളിൽ പിന്തുടരാൻ എളുപ്പമാണ്, പ്രത്യേകിച്ച് നമ്പറുകൾ, തീയതികൾ, സ്ഥിരീകരണങ്ങൾ എന്നിവയ്ക്ക്.
ElevenLabs-നിർദ്ദിഷ്ട നിയന്ത്രണങ്ങൾ
Stability, similarity boost, style exaggeration, speaker boost എന്നിവ ElevenLabs വോയ്സ് നിയന്ത്രണങ്ങളാണ്:
- Stability ഒരു വാക്യത്തിൽ നിന്ന് അടുത്തതിലേക്ക് വോയ്സ് എത്ര സ്ഥിരതയോടെ കേൾക്കുന്നുവെന്ന് നിയന്ത്രിക്കുന്നു — ഉയർന്നത് കൂടുതൽ സ്ഥിരം, കുറഞ്ഞത് കൂടുതൽ സ്വാഭാവിക വ്യതിയാനം അനുവദിക്കുന്നു.
- Similarity boost ഔട്ട്പുട്ടിനെ ഉറവിട വോയ്സിനോട് അടുത്ത് നിലനിർത്തുന്നു.
- Speaker boost യഥാർത്ഥ സംസാരിക്കുന്നയാളുമായുള്ള സാമ്യം വർദ്ധിപ്പിക്കുന്നു.
മാറ്റങ്ങൾ പേപ്പറിലല്ല, ഉറക്കെ ടെസ്റ്റ് ചെയ്യുക. ഓരോ ക്രമീകരണത്തിനു ശേഷവും /agent/interface-ലെ വോയ്സ് ടെസ്റ്റ് ഉപയോഗിക്കുക — speed-ഉം ഉച്ചാരണ പ്രശ്നങ്ങളും കേൾക്കുമ്പോൾ സെക്കൻഡുകൾക്കുള്ളിൽ വ്യക്തമാകും.