ഭാഷാ മോഡൽ (LLM)
LLM ടാബ് നിങ്ങളുടെ ഏജന്റ് എങ്ങനെ ചിന്തിക്കുന്നുവെന്നും അതിന്റെ വോയ്സ് പൈപ്പ്ലൈൻ എങ്ങനെ ബന്ധിപ്പിച്ചിരിക്കുന്നുവെന്നും തീരുമാനിക്കുന്നു. ഇത് വോയ്സ് പൈപ്പ്ലൈൻ മോഡ് (speech-to-text, ഭാഷാ മോഡൽ, text-to-speech എന്നിവ എങ്ങനെ ഒത്തുചേരുന്നു), ഏത് LLM പ്രൊവൈഡറും മോഡലും സംഭാഷണത്തെ നയിക്കുന്നു, ജനറേഷൻ പാരാമീറ്ററുകൾ, ഒരു fallback മോഡൽ, RAG / knowledge-base ലിങ്കിംഗ് എന്നിവ നിയന്ത്രിക്കുന്നു. /agent/setup-ലെ ഏജന്റ് ബിൽഡറിൽ ഇത് സജ്ജമാക്കുക.
വോയ്സ് പൈപ്പ്ലൈൻ മോഡ്
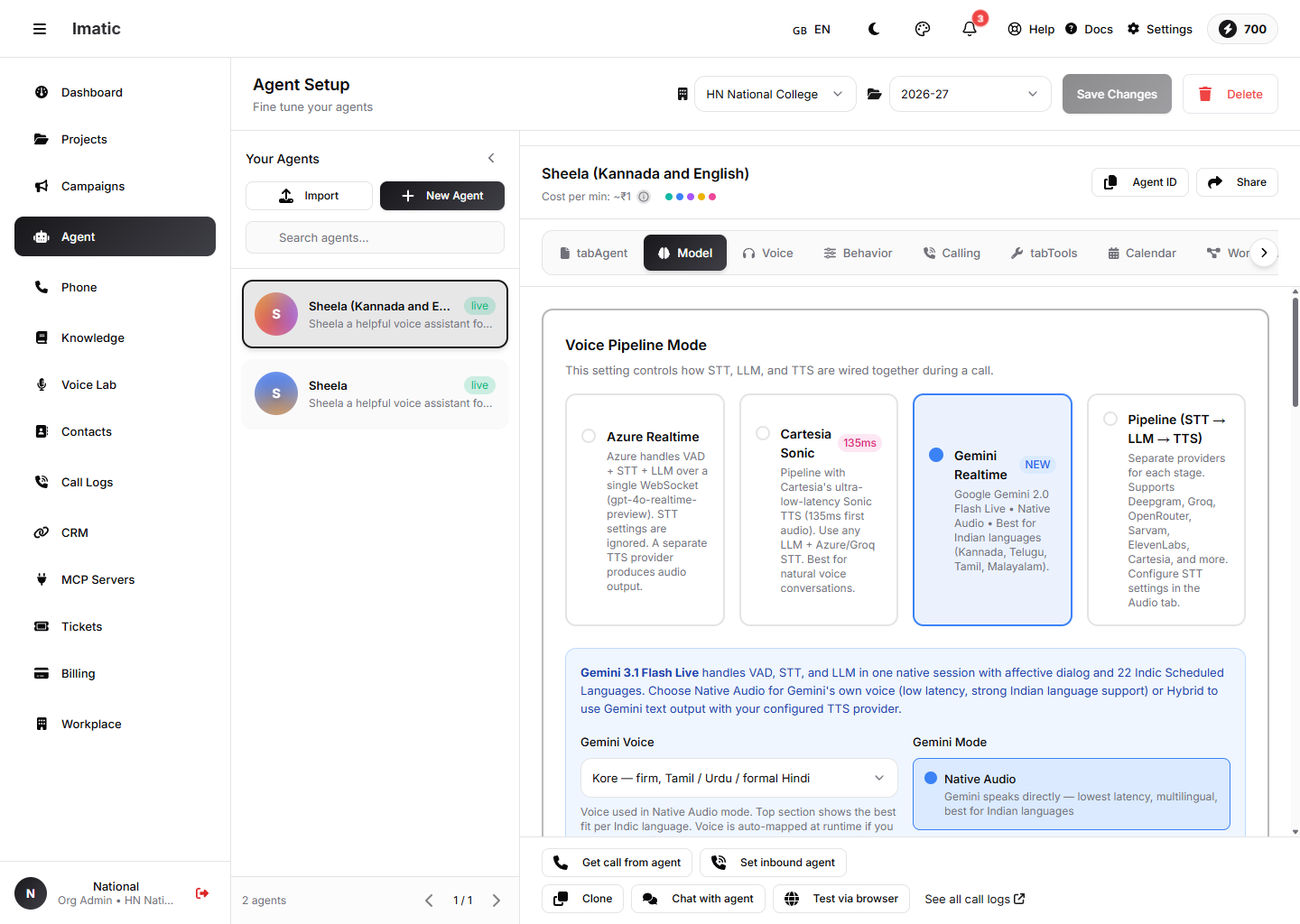 Model ടാബ്: ഒരു Voice Pipeline Mode തിരഞ്ഞെടുക്കുക — Azure Realtime, Cartesia Sonic, Gemini Realtime, അല്ലെങ്കിൽ ഒരു പ്രത്യേക STT→LLM→TTS Pipeline.
Model ടാബ്: ഒരു Voice Pipeline Mode തിരഞ്ഞെടുക്കുക — Azure Realtime, Cartesia Sonic, Gemini Realtime, അല്ലെങ്കിൽ ഒരു പ്രത്യേക STT→LLM→TTS Pipeline.
ഈ ടാബിലെ ഏറ്റവും പ്രധാനപ്പെട്ട ക്രമീകരണമാണിത് — ഒരു കോളിനിടെ STT, LLM, TTS എന്നിവ എങ്ങനെ ഒന്നിച്ച് ബന്ധിപ്പിക്കുന്നുവെന്ന് ഇത് നിയന്ത്രിക്കുന്നു. നാല് മോഡുകളിൽ ഒന്ന് തിരഞ്ഞെടുക്കുക:
- Azure Realtime (ഡിഫോൾട്ട്) — Azure ഒരു
gpt-4o-realtime-previewഡിപ്ലോയ്മെന്റ് ഉപയോഗിച്ച് ഒറ്റ WebSocket-ലൂടെ voice-activity detection, speech-to-text, LLM എന്നിവ കൈകാര്യം ചെയ്യുന്നു. Audio ടാബിലെ STT ക്രമീകരണങ്ങൾ അവഗണിക്കപ്പെടുന്നു; ഓഡിയോ ഉൽപ്പാദിപ്പിക്കുന്നത് ഒരു പ്രത്യേക TTS പ്രൊവൈഡറാണ്. - Cartesia Sonic — ഏത് LLM-ഉം ഒരു Azure/Groq STT-ഉം ഉപയോഗിച്ച് Cartesia-യുടെ അൾട്രാ-ലോ-ലേറ്റൻസി Sonic TTS ഉപയോഗിക്കുന്ന ഒരു പൈപ്പ്ലൈൻ.
- Gemini Realtime — Google Gemini Live VAD, STT, LLM എന്നിവ സ്വാഭാവികമായി കൈകാര്യം ചെയ്യുന്നു, ഇന്ത്യൻ ഭാഷകൾക്ക് ശക്തമായ പിന്തുണയോടെ. ഇതിന് സ്വന്തം വോയ്സിൽ സംസാരിക്കാം (Native Audio) അല്ലെങ്കിൽ നിങ്ങൾ ക്രമീകരിച്ച TTS-നായി ടെക്സ്റ്റ് ഔട്ട്പുട്ട് ചെയ്യാം (Hybrid).
- Pipeline (STT → LLM → TTS) — ഓരോ ഘട്ടത്തിനും വെവ്വേറെ പ്രൊവൈഡർമാർ, സ്വതന്ത്രമായി ക്രമീകരിക്കുന്നു. ട്രാൻസ്ക്രൈബർ, മോഡൽ, വോയ്സ് എന്നിവയിൽ പൂർണ്ണ നിയന്ത്രണം വേണമെങ്കിൽ ഇത് ഉപയോഗിക്കുക.
ഓരോ റിയൽടൈം മോഡിനും ഒരു നിർദ്ദിഷ്ട മോഡൽ കുടുംബം ആവശ്യമാണ്, മോഡൽ നേരിട്ട് റിയൽടൈം പ്രൊവൈഡറിലേക്ക് കൈമാറുന്നു — ഒരു അനുയോജ്യമല്ലാത്ത മൂല്യം കോൾ സമയത്ത് പരാജയപ്പെടുന്നു. നിങ്ങൾ മോഡുകൾ മാറുമ്പോൾ ബിൽഡർ അനുയോജ്യമായ ഒരു മോഡൽ സ്വയമേവ സജ്ജമാക്കുന്നു, സേവിൽ അത് മോഡലിനെ മോഡുമായി പൊരുത്തപ്പെടുത്തുന്നു. പ്രത്യേകിച്ച്, gpt-4 പോലുള്ള ഒരു സാധാരണ ചാറ്റ് മോഡൽ ഡിഫോൾട്ട് Azure Realtime മോഡിന് സാധുവല്ല, സേവിൽ അത് മാറ്റിയെഴുതപ്പെടുന്നു; റിയൽടൈം മോഡുകൾക്ക് ഒരു റിയൽടൈം ഡിപ്ലോയ്മെന്റും Pipeline / Cartesia Sonic-ന് ഒരു chat-completion മോഡലും തിരഞ്ഞെടുക്കുക.
പ്രൊവൈഡറും മോഡലും തിരഞ്ഞെടുക്കുക
പൂർണ്ണമായി മാനേജ് ചെയ്യപ്പെടുന്ന റിയൽടൈം മോഡുകൾക്ക് പുറത്ത്, നിങ്ങൾ LLM പ്രൊവൈഡറും പിന്നെ ആ പ്രൊവൈഡറിനായി ഒരു മോഡലും തിരഞ്ഞെടുക്കുന്നു. നിങ്ങളുടെ ഓർഗനൈസേഷൻ ക്രെഡൻഷ്യലുകൾ പ്രവർത്തനക്ഷമമാക്കിയ പ്രൊവൈഡർമാരെ മാത്രമേ പ്രൊവൈഡർ ലിസ്റ്റ് കാണിക്കൂ (Settings-ൽ ക്രമീകരിക്കുന്നു). പ്രവർത്തനക്ഷമമാക്കിയതിനെ ആശ്രയിച്ച്, അതിൽ Azure OpenAI, Google Gemini, Groq, OpenRouter, Sarvam എന്നിവയും ഉൾപ്പെടാം.
- Azure-ന്, മോഡൽ ഓപ്ഷനുകൾ നിങ്ങൾ ക്രമീകരിച്ച ഡിപ്ലോയ്മെന്റുകളിൽ നിന്നാണ് വരുന്നത് (ഓരോ ക്രെഡൻഷ്യലും ഒരു ഡിപ്ലോയ്മെന്റാണ്).
- സിംഗിൾ-കീ പ്രൊവൈഡർമാർക്ക്, മോഡൽ ലിസ്റ്റ് പ്ലാറ്റ്ഫോമിന്റെ മോഡൽ കാറ്റലോഗിൽ നിന്നാണ് വരുന്നത്.
ജോലിക്ക് അനുയോജ്യമായ മോഡൽ തിരഞ്ഞെടുക്കുക: ഉയർന്ന ശേഷിയുള്ള മോഡലുകൾ സങ്കീർണ്ണമായ കോളുകളിൽ മികച്ച രീതിയിൽ ന്യായവാദം ചെയ്യുന്നു, ലഘുവായ മോഡലുകൾ വേഗത്തിൽ പ്രതികരിക്കുകയും ഓരോ കോളിനും കുറഞ്ഞ ചെലവ് വരുത്തുകയും ചെയ്യുന്നു. മിക്ക കോളിംഗ് ഏജന്റുകൾക്കും, latency ശുദ്ധമായ ഗുണനിലവാരത്തെപ്പോലെ തന്നെ പ്രധാനമാണ്.
മോഡൽ പാരാമീറ്ററുകൾ
Model Parameters വിഭാഗം ജനറേഷൻ നിയന്ത്രിക്കുന്നു:
- Tokens — ഓരോ ടേണിലും മോഡൽ എത്ര ജനറേറ്റ് ചെയ്യുന്നുവെന്ന് പരിമിതപ്പെടുത്തുന്നു. ഏജന്റ് ഒരു ഫോൺ കോളിൽ വാചാലമാകാതിരിക്കാൻ ഇത് മിതമായി വയ്ക്കുക.
- Temperature — മറുപടികൾ എത്ര വൈവിധ്യമുള്ളതാണ്. സ്ക്രിപ്റ്റ് ചെയ്ത, compliance-സെൻസിറ്റീവ് കോളുകൾക്ക് കുറവ്; സംഭാഷണ ഔട്ട്റീച്ചിന് ഉയർന്നത്.
- Top P — nucleus-sampling കട്ട്ഓഫ്, വൈവിധ്യം നിയന്ത്രിക്കാനുള്ള ഒരു ബദൽ മാർഗ്ഗം.
- Frequency penalty ഉം presence penalty ഉം — ആവർത്തനം നിരുത്സാഹപ്പെടുത്തുകയും പുതിയ വിഷയങ്ങൾ അവതരിപ്പിക്കാൻ മോഡലിനെ പ്രോത്സാഹിപ്പിക്കുകയും ചെയ്യുന്നു.
വിപുലമായ ക്രമീകരണങ്ങൾ
Advanced Settings വിഭാഗം ഓപ്പറേഷണൽ നിയന്ത്രണങ്ങൾ ചേർക്കുന്നു:
- Timeout (ms) — ഒരു ടേണിൽ ഉപേക്ഷിക്കുന്നതിന് മുമ്പ് മോഡലിനായി എത്ര നേരം കാത്തിരിക്കണം.
- Retry count ഉം retry delay (ms) ഉം — പരാജയപ്പെട്ട ഒരു അഭ്യർത്ഥന ഏജന്റ് എങ്ങനെ വീണ്ടും ശ്രമിക്കുന്നു.
- Response format — Text അല്ലെങ്കിൽ JSON.
- Stream enabled — ടോക്കണുകൾ ജനറേറ്റ് ചെയ്യപ്പെടുമ്പോൾ തന്നെ സ്ട്രീം ചെയ്യുക (ഡിഫോൾട്ടായി ഓൺ), കുറഞ്ഞ അനുഭവപ്പെടുന്ന latency-ക്കായി.
- JSON mode — ഘടനാപരമായ JSON ഔട്ട്പുട്ട് നിർബന്ധമാക്കുക.
- Cost tracking — ഈ ഏജന്റിനായുള്ള ടോക്കൺ ചെലവ് രേഖപ്പെടുത്തുക.
Custom Parameters-ന് കീഴിൽ റോ JSON ആയി അധിക പ്രൊവൈഡർ പാരാമീറ്ററുകളും നിങ്ങൾക്ക് നൽകാം.
Fallback മോഡൽ
പ്രാഥമിക മോഡൽ ലഭ്യമല്ലെങ്കിൽ കോളുകൾ പ്രവർത്തിക്കുന്നത് തുടരാൻ ഒരു fallback പ്രൊവൈഡറും മോഡലും സജ്ജമാക്കുക. പ്രാഥമിക മോഡലിന് പ്രതികരിക്കാൻ കഴിയുന്നില്ലെങ്കിൽ, സംഭാഷണം ഉപേക്ഷിക്കുന്നതിന് പകരം ഏജന്റ് fallback ഉപയോഗിക്കുന്നു — ഒരു ഏജന്റിനെ പ്രതിരോധശേഷിയുള്ളതാക്കാനുള്ള ഏറ്റവും ലളിതമായ മാർഗ്ഗം.
Knowledge base & RAG
Retrieval-augmented generation ഇവിടെ, LLM ടാബിൽ, Add Knowledge Base വിഭാഗത്തിലാണ് ക്രമീകരിക്കുന്നത്. RAG Enabled ഓൺ ചെയ്യുക, ഒന്നോ അതിലധികമോ knowledge bases തിരഞ്ഞെടുക്കുക, തുടർന്ന് RAG Top K (എത്ര ഭാഗങ്ങൾ വീണ്ടെടുക്കണം) ഉം similarity threshold (ഒരു ഭാഗം എത്ര അടുത്ത് പൊരുത്തപ്പെടണം) ഉം ട്യൂൺ ചെയ്യുക. ഇവ എങ്ങനെ ട്യൂൺ ചെയ്യാമെന്നും ആദ്യം ഒരു knowledge base എങ്ങനെ നിർമ്മിക്കാമെന്നും അറിയാൻ Knowledge & RAG കാണുക.
ഉപയോഗവും ചെലവും ട്രാക്ക് ചെയ്യൽ
മോഡൽ ഉപയോഗം നിങ്ങളുടെ ഓർഗനൈസേഷന്റെ പ്രീപെയ്ഡ് ബാലൻസിൽ നിന്ന് ക്രെഡിറ്റ് ഉപയോഗിക്കുന്നു. നിങ്ങളുടെ ഏജന്റുകളിലുടനീളം ഉപഭോഗവും ചെലവും കാണാൻ, Billing ഉപയോഗിക്കുക — Overview പ്ലാനും ഉപയോഗവും കാണിക്കുന്നു, Wallet നിങ്ങളുടെ പ്രീപെയ്ഡ് ക്രെഡിറ്റ്, ടോപ്പ്-അപ്പുകൾ, ചരിത്രം എന്നിവ കാണിക്കുന്നു. കാര്യക്ഷമമായ മോഡലുകളും ന്യായമായ ടോക്കൺ പരിധികളും തിരഞ്ഞെടുക്കുന്നതാണ് ചെലവ് നിയന്ത്രിക്കാനുള്ള ഏറ്റവും നേരിട്ടുള്ള മാർഗ്ഗം.