ಭಾಷಾ ಮಾದರಿ (LLM)
LLM ಟ್ಯಾಬ್ ನಿಮ್ಮ ಏಜೆಂಟ್ ಹೇಗೆ ಯೋಚಿಸುತ್ತದೆ ಮತ್ತು ಅದರ ಧ್ವನಿ ಪೈಪ್ಲೈನ್ ಹೇಗೆ ವೈರ್ ಆಗಿದೆ ಎಂಬುದನ್ನು ನಿರ್ಧರಿಸುತ್ತದೆ. ಇದು voice pipeline mode (ಸ್ಪೀಚ್-ಟು-ಟೆಕ್ಸ್ಟ್, ಭಾಷಾ ಮಾದರಿ ಮತ್ತು ಟೆಕ್ಸ್ಟ್-ಟು-ಸ್ಪೀಚ್ ಹೇಗೆ ಒಟ್ಟಿಗೆ ಹೊಂದುತ್ತವೆ), ಯಾವ LLM provider and model ಸಂಭಾಷಣೆಯನ್ನು ಚಾಲನೆ ಮಾಡುತ್ತದೆ, ಉತ್ಪಾದನಾ ನಿಯತಾಂಕಗಳು, fallback ಮಾದರಿ, ಮತ್ತು RAG / knowledge-base ಲಿಂಕ್ ಅನ್ನು ನಿಯಂತ್ರಿಸುತ್ತದೆ. ಇದನ್ನು ಏಜೆಂಟ್ ಬಿಲ್ಡರ್ನಲ್ಲಿ /agent/setup ನಲ್ಲಿ ಹೊಂದಿಸಿ.
ಧ್ವನಿ ಪೈಪ್ಲೈನ್ ಮೋಡ್
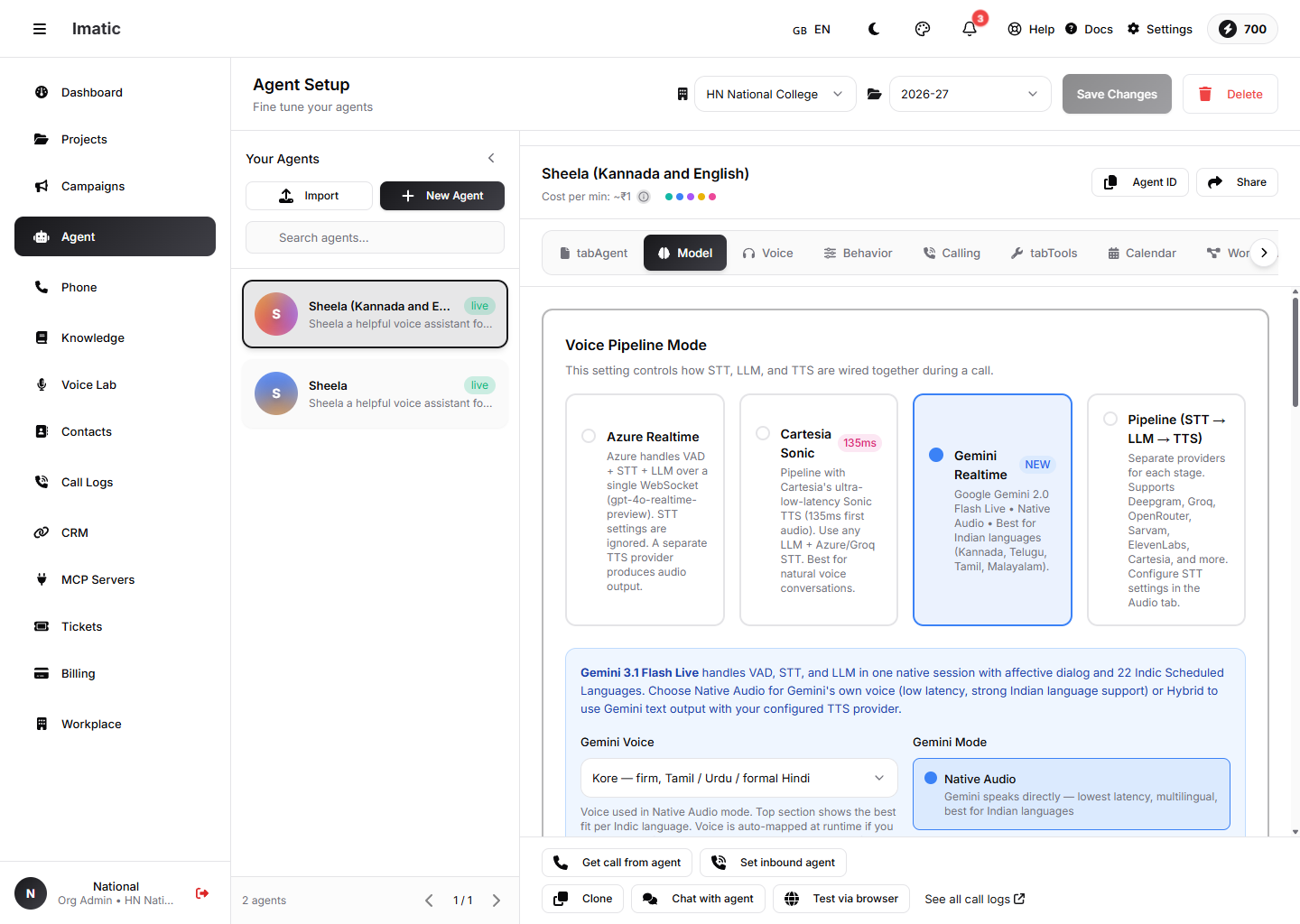 Model ಟ್ಯಾಬ್: Voice Pipeline Mode ಆಯ್ಕೆಮಾಡಿ — Azure Realtime, Cartesia Sonic, Gemini Realtime, ಅಥವಾ ಪ್ರತ್ಯೇಕ STT→LLM→TTS Pipeline.
Model ಟ್ಯಾಬ್: Voice Pipeline Mode ಆಯ್ಕೆಮಾಡಿ — Azure Realtime, Cartesia Sonic, Gemini Realtime, ಅಥವಾ ಪ್ರತ್ಯೇಕ STT→LLM→TTS Pipeline.
ಇದು ಟ್ಯಾಬ್ನಲ್ಲಿ ಅತ್ಯಂತ ಮುಖ್ಯವಾದ ಸೆಟ್ಟಿಂಗ್ — ಕರೆಯ ಸಮಯದಲ್ಲಿ STT, LLM ಮತ್ತು TTS ಹೇಗೆ ಒಟ್ಟಿಗೆ ವೈರ್ ಆಗುತ್ತವೆ ಎಂಬುದನ್ನು ಇದು ನಿಯಂತ್ರಿಸುತ್ತದೆ. ನಾಲ್ಕು ಮೋಡ್ಗಳಲ್ಲಿ ಒಂದನ್ನು ಆಯ್ಕೆಮಾಡಿ:
- Azure Realtime (ಡೀಫಾಲ್ಟ್) — Azure ಒಂದೇ WebSocket ಮೂಲಕ
gpt-4o-realtime-previewಡಿಪ್ಲಾಯ್ಮೆಂಟ್ ಬಳಸಿ ಧ್ವನಿ-ಚಟುವಟಿಕೆ ಪತ್ತೆ, ಸ್ಪೀಚ್-ಟು-ಟೆಕ್ಸ್ಟ್ ಮತ್ತು LLM ಅನ್ನು ನಿರ್ವಹಿಸುತ್ತದೆ. Audio ಟ್ಯಾಬ್ನ STT ಸೆಟ್ಟಿಂಗ್ಗಳನ್ನು ನಿರ್ಲಕ್ಷಿಸಲಾಗುತ್ತದೆ; ಒಂದು ಪ್ರತ್ಯೇಕ TTS ಪೂರೈಕೆದಾರ ಆಡಿಯೋವನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ. - Cartesia Sonic — Cartesia ನ ಅತಿ-ಕಡಿಮೆ-ಲೇಟೆನ್ಸಿ Sonic TTS ಬಳಸುವ ಒಂದು ಪೈಪ್ಲೈನ್, ಯಾವುದೇ LLM ಮತ್ತು Azure/Groq STT ಯೊಂದಿಗೆ.
- Gemini Realtime — Google Gemini Live VAD, STT ಮತ್ತು LLM ಅನ್ನು ಸ್ಥಳೀಯವಾಗಿ ನಿರ್ವಹಿಸುತ್ತದೆ, ಭಾರತೀಯ ಭಾಷೆಗಳಿಗೆ ಬಲವಾದ ಬೆಂಬಲದೊಂದಿಗೆ. ಇದು ತನ್ನದೇ ಧ್ವನಿಯಲ್ಲಿ ಮಾತನಾಡಬಹುದು (Native Audio) ಅಥವಾ ನಿಮ್ಮ ಕಾನ್ಫಿಗರ್ ಮಾಡಿದ TTS ಗಾಗಿ ಪಠ್ಯವನ್ನು ಔಟ್ಪುಟ್ ಮಾಡಬಹುದು (Hybrid).
- Pipeline (STT → LLM → TTS) — ಪ್ರತಿ ಹಂತಕ್ಕೂ ಪ್ರತ್ಯೇಕ ಪೂರೈಕೆದಾರರು, ಸ್ವತಂತ್ರವಾಗಿ ಕಾನ್ಫಿಗರ್ ಆಗಿರುತ್ತಾರೆ. ಟ್ರಾನ್ಸ್ಕ್ರೈಬರ್, ಮಾದರಿ ಮತ್ತು ಧ್ವನಿಯ ಮೇಲೆ ಸಂಪೂರ್ಣ ನಿಯಂತ್ರಣ ಬಯಸಿದಾಗ ಇದನ್ನು ಬಳಸಿ.
ಪ್ರತಿ ರಿಯಲ್ಟೈಮ್ ಮೋಡ್ಗೆ ಮಾದರಿಗಳ ನಿರ್ದಿಷ್ಟ ಕುಟುಂಬ ಬೇಕಾಗುತ್ತದೆ, ಮತ್ತು ಮಾದರಿಯನ್ನು ನೇರವಾಗಿ ರಿಯಲ್ಟೈಮ್ ಪೂರೈಕೆದಾರನಿಗೆ ರವಾನಿಸಲಾಗುತ್ತದೆ — ಹೊಂದಾಣಿಕೆಯಾಗದ ಮೌಲ್ಯ ಕರೆಯ ಸಮಯದಲ್ಲಿ ವಿಫಲಗೊಳ್ಳುತ್ತದೆ. ನೀವು ಮೋಡ್ಗಳನ್ನು ಬದಲಾಯಿಸಿದಾಗ ಬಿಲ್ಡರ್ ಸ್ವಯಂಚಾಲಿತವಾಗಿ ಹೊಂದಾಣಿಕೆಯ ಮಾದರಿಯನ್ನು ಹೊಂದಿಸುತ್ತದೆ, ಮತ್ತು ಉಳಿಸುವಾಗ ಅದು ಮಾದರಿಯನ್ನು ಮೋಡ್ಗೆ ಸಮನ್ವಯಗೊಳಿಸುತ್ತದೆ. ನಿರ್ದಿಷ್ಟವಾಗಿ, gpt-4 ನಂತಹ ಸರಳ ಚಾಟ್ ಮಾದರಿ ಡೀಫಾಲ್ಟ್ Azure Realtime ಮೋಡ್ಗೆ ಮಾನ್ಯ ಅಲ್ಲ ಮತ್ತು ಉಳಿಸುವಾಗ ಮರುಬರೆಯಲಾಗುತ್ತದೆ; ರಿಯಲ್ಟೈಮ್ ಮೋಡ್ಗಳಿಗೆ ರಿಯಲ್ಟೈಮ್ ಡಿಪ್ಲಾಯ್ಮೆಂಟ್ ಆಯ್ಕೆಮಾಡಿ, ಮತ್ತು Pipeline / Cartesia Sonic ಗಾಗಿ ಚಾಟ್-ಕಂಪ್ಲೀಷನ್ ಮಾದರಿಯನ್ನು ಆಯ್ಕೆಮಾಡಿ.
ಪೂರೈಕೆದಾರ ಮತ್ತು ಮಾದರಿಯನ್ನು ಆಯ್ಕೆಮಾಡಿ
ಸಂಪೂರ್ಣ-ನಿರ್ವಹಿಸಲ್ಪಟ್ಟ ರಿಯಲ್ಟೈಮ್ ಮೋಡ್ಗಳ ಹೊರಗೆ, ನೀವು LLM provider ಅನ್ನು ಮತ್ತು ನಂತರ ಆ ಪೂರೈಕೆದಾರನಿಗೆ ಒಂದು model ಅನ್ನು ಆಯ್ಕೆಮಾಡುತ್ತೀರಿ. ಪೂರೈಕೆದಾರ ಪಟ್ಟಿ ನಿಮ್ಮ ಸಂಸ್ಥೆ ಸಕ್ರಿಯಗೊಳಿಸಿದ ಕ್ರೆಡೆನ್ಷಿಯಲ್ಗಳಿರುವ ಪೂರೈಕೆದಾರರನ್ನು ಮಾತ್ರ ತೋರಿಸುತ್ತದೆ (Settings ನಲ್ಲಿ ಕಾನ್ಫಿಗರ್ ಮಾಡಲಾಗಿದೆ). ಯಾವುದು ಸಕ್ರಿಯಗೊಂಡಿದೆ ಎಂಬುದನ್ನು ಅವಲಂಬಿಸಿ, ಅದು ಇತರ ಹಲವುಗಳ ಜೊತೆಗೆ Azure OpenAI, Google Gemini, Groq, OpenRouter ಮತ್ತು Sarvam ಅನ್ನು ಒಳಗೊಂಡಿರಬಹುದು.
- Azure ಗಾಗಿ, ಮಾದರಿ ಆಯ್ಕೆಗಳು ನಿಮ್ಮ ಕಾನ್ಫಿಗರ್ ಮಾಡಿದ ಡಿಪ್ಲಾಯ್ಮೆಂಟ್ಗಳಿಂದ ಬರುತ್ತವೆ (ಪ್ರತಿ ಕ್ರೆಡೆನ್ಷಿಯಲ್ ಒಂದು ಡಿಪ್ಲಾಯ್ಮೆಂಟ್).
- ಸಿಂಗಲ್-ಕೀ ಪೂರೈಕೆದಾರರಿಗೆ, ಮಾದರಿ ಪಟ್ಟಿ ಪ್ಲಾಟ್ಫಾರ್ಮ್ನ ಮಾದರಿ ಕ್ಯಾಟಲಾಗ್ನಿಂದ ಬರುತ್ತದೆ.
ಕೆಲಸಕ್ಕೆ ಹೊಂದುವ ಮಾದರಿಯನ್ನು ಆಯ್ಕೆಮಾಡಿ: ಹೆಚ್ಚಿನ-ಸಾಮರ್ಥ್ಯದ ಮಾದರಿಗಳು ಸಂಕೀರ್ಣ ಕರೆಗಳಲ್ಲಿ ಉತ್ತಮವಾಗಿ ತರ್ಕಿಸುತ್ತವೆ, ಆದರೆ ಹಗುರ ಮಾದರಿಗಳು ವೇಗವಾಗಿ ಪ್ರತಿಕ್ರಿಯಿಸುತ್ತವೆ ಮತ್ತು ಪ್ರತಿ ಕರೆಗೆ ಕಡಿಮೆ ವೆಚ್ಚವಾಗುತ್ತದೆ. ಹೆಚ್ಚಿನ ಕರೆ ಮಾಡುವ ಏಜೆಂಟ್ಗಳಿಗೆ, ಶುದ್ಧ ಗುಣಮಟ್ಟದಷ್ಟೇ ಲೇಟೆನ್ಸಿಯೂ ಮುಖ್ಯ.
ಮಾದರಿ ನಿಯತಾಂಕಗಳು
Model Parameters ವಿಭಾಗ ಉತ್ಪಾದನೆಯನ್ನು ನಿಯಂತ್ರಿಸುತ್ತದೆ:
- Tokens — ಪ್ರತಿ ಸರದಿಗೆ ಮಾದರಿ ಎಷ್ಟು ಉತ್ಪಾದಿಸುತ್ತದೆ ಎಂಬುದನ್ನು ಮಿತಿಗೊಳಿಸುತ್ತದೆ. ಫೋನ್ ಕರೆಯಲ್ಲಿ ಏಜೆಂಟ್ ಹರಟೆ ಹೊಡೆಯದಂತೆ ಇದನ್ನು ಸಾಧಾರಣವಾಗಿ ಇರಿಸಿ.
- Temperature — ಪ್ರತ್ಯುತ್ತರಗಳು ಎಷ್ಟು ವೈವಿಧ್ಯಮಯ. ಸ್ಕ್ರಿಪ್ಟೆಡ್, ಅನುಸರಣೆ-ಸೂಕ್ಷ್ಮ ಕರೆಗಳಿಗೆ ಕಡಿಮೆ; ಸಂಭಾಷಣಾ ಔಟ್ರೀಚ್ಗೆ ಹೆಚ್ಚು.
- Top P — ನ್ಯೂಕ್ಲಿಯಸ್-ಸ್ಯಾಂಪ್ಲಿಂಗ್ ಕಟ್ಆಫ್, ವೈವಿಧ್ಯವನ್ನು ನಿಯಂತ್ರಿಸುವ ಪರ್ಯಾಯ ಮಾರ್ಗ.
- Frequency penalty ಮತ್ತು presence penalty — ಪುನರಾವರ್ತನೆಯನ್ನು ನಿರುತ್ಸಾಹಗೊಳಿಸುತ್ತವೆ ಮತ್ತು ಮಾದರಿ ಹೊಸ ವಿಷಯಗಳನ್ನು ಪರಿಚಯಿಸಲು ಪ್ರೋತ್ಸಾಹಿಸುತ್ತವೆ.
ಸುಧಾರಿತ ಸೆಟ್ಟಿಂಗ್ಗಳು
Advanced Settings ವಿಭಾಗ ಕಾರ್ಯಾಚರಣಾ ನಿಯಂತ್ರಣಗಳನ್ನು ಸೇರಿಸುತ್ತದೆ:
- Timeout (ms) — ಒಂದು ಸರದಿಯನ್ನು ಬಿಟ್ಟುಕೊಡುವ ಮೊದಲು ಮಾದರಿಗಾಗಿ ಎಷ್ಟು ಸಮಯ ಕಾಯಬೇಕು.
- Retry count ಮತ್ತು retry delay (ms) — ವಿಫಲ ವಿನಂತಿಯನ್ನು ಏಜೆಂಟ್ ಹೇಗೆ ಮರುಪ್ರಯತ್ನಿಸುತ್ತದೆ.
- Response format — Text ಅಥವಾ JSON.
- Stream enabled — ಟೋಕನ್ಗಳನ್ನು ಉತ್ಪಾದಿಸಿದಂತೆ ಸ್ಟ್ರೀಮ್ ಮಾಡಿ (ಡೀಫಾಲ್ಟ್ ಆಗಿ ಆನ್) ಕಡಿಮೆ ಗ್ರಹಿಸಿದ ಲೇಟೆನ್ಸಿಗಾಗಿ.
- JSON mode — ರಚನಾತ್ಮಕ JSON ಔಟ್ಪುಟ್ ಅನ್ನು ಒತ್ತಾಯಿಸಿ.
- Cost tracking — ಈ ಏಜೆಂಟ್ಗೆ ಟೋಕನ್ ಖರ್ಚನ್ನು ದಾಖಲಿಸಿ.
Custom Parameters ಅಡಿಯಲ್ಲಿ ನೀವು ಹೆಚ್ಚುವರಿ ಪೂರೈಕೆದಾರ ನಿಯತಾಂಕಗಳನ್ನು ಕಚ್ಚಾ JSON ಆಗಿ ಸಹ ಒದಗಿಸಬಹುದು.
Fallback ಮಾದರಿ
ಪ್ರಾಥಮಿಕ ಲಭ್ಯವಿಲ್ಲದಿದ್ದರೆ ಕರೆಗಳು ಕೆಲಸ ಮಾಡುತ್ತಿರುವಂತೆ fallback provider and model ಅನ್ನು ಹೊಂದಿಸಿ. ಪ್ರಾಥಮಿಕ ಪ್ರತಿಕ್ರಿಯಿಸಲು ಸಾಧ್ಯವಾಗದಿದ್ದರೆ, ಏಜೆಂಟ್ ಸಂಭಾಷಣೆಯನ್ನು ಬಿಡುವ ಬದಲು fallback ಅನ್ನು ಬಳಸುತ್ತದೆ — ಏಜೆಂಟ್ ಅನ್ನು ಸ್ಥಿತಿಸ್ಥಾಪಕವಾಗಿ ಮಾಡುವ ಸರಳ ಮಾರ್ಗ.
ನಾಲೆಡ್ಜ್ ಬೇಸ್ ಮತ್ತು RAG
ಮರುಪಡೆಯುವಿಕೆ-ವರ್ಧಿತ ಉತ್ಪಾದನೆಯನ್ನು ಇಲ್ಲಿ, LLM ಟ್ಯಾಬ್ನಲ್ಲಿ, Add Knowledge Base ವಿಭಾಗದಲ್ಲಿ ಕಾನ್ಫಿಗರ್ ಮಾಡಲಾಗಿದೆ. RAG Enabled ಅನ್ನು ಆನ್ ಮಾಡಿ, ಒಂದು ಅಥವಾ ಹೆಚ್ಚು ನಾಲೆಡ್ಜ್ ಬೇಸ್ಗಳನ್ನು ಆಯ್ಕೆಮಾಡಿ, ಮತ್ತು RAG Top K (ಎಷ್ಟು ಭಾಗಗಳನ್ನು ಮರುಪಡೆಯಬೇಕು) ಮತ್ತು similarity threshold (ಒಂದು ಭಾಗ ಎಷ್ಟು ನಿಕಟವಾಗಿ ಹೊಂದಾಣಿಕೆಯಾಗಬೇಕು) ಅನ್ನು ಹೊಂದಿಸಿ. ಇವುಗಳನ್ನು ಹೇಗೆ ಹೊಂದಿಸುವುದು ಮತ್ತು ಮೊದಲು ನಾಲೆಡ್ಜ್ ಬೇಸ್ ಅನ್ನು ಹೇಗೆ ನಿರ್ಮಿಸುವುದು ಎಂಬುದಕ್ಕೆ Knowledge ಮತ್ತು RAG ನೋಡಿ.
ಬಳಕೆ ಮತ್ತು ವೆಚ್ಚವನ್ನು ಟ್ರ್ಯಾಕ್ ಮಾಡುವುದು
ಮಾದರಿ ಬಳಕೆ ನಿಮ್ಮ ಸಂಸ್ಥೆಯ ಪ್ರೀಪೇಯ್ಡ್ ಬ್ಯಾಲೆನ್ಸ್ನಿಂದ ಕ್ರೆಡಿಟ್ಗಳನ್ನು ಬಳಸುತ್ತದೆ. ನಿಮ್ಮ ಏಜೆಂಟ್ಗಳಾದ್ಯಂತ ಬಳಕೆ ಮತ್ತು ಖರ್ಚನ್ನು ನೋಡಲು, Billing ಬಳಸಿ — Overview ಪ್ಲಾನ್ ಮತ್ತು ಬಳಕೆಯನ್ನು ತೋರಿಸುತ್ತದೆ, ಮತ್ತು Wallet ನಿಮ್ಮ ಪ್ರೀಪೇಯ್ಡ್ ಕ್ರೆಡಿಟ್, ಟಾಪ್-ಅಪ್ಗಳು ಮತ್ತು ಇತಿಹಾಸವನ್ನು ತೋರಿಸುತ್ತದೆ. ದಕ್ಷ ಮಾದರಿಗಳು ಮತ್ತು ಸಮಂಜಸ ಟೋಕನ್ ಮಿತಿಗಳನ್ನು ಆಯ್ಕೆಮಾಡುವುದು ವೆಚ್ಚವನ್ನು ನಿಯಂತ್ರಿಸಲು ಅತ್ಯಂತ ನೇರ ಮಾರ್ಗ.