भाषा मॉडल (LLM)
LLM टैब तय करता है कि आपका एजेंट कैसे सोचता है और इसकी वॉयस पाइपलाइन कैसे जुड़ी है। यह वॉयस पाइपलाइन मोड (speech-to-text, भाषा मॉडल और text-to-speech कैसे एक साथ फ़िट होते हैं), कौन-सा LLM प्रदाता और मॉडल बातचीत को संचालित करता है, निर्माण पैरामीटर, एक फ़ॉलबैक मॉडल, और RAG / ज्ञान-आधार लिंकेज को नियंत्रित करता है। इसे एजेंट बिल्डर में /agent/setup पर सेट करें।
वॉयस पाइपलाइन मोड
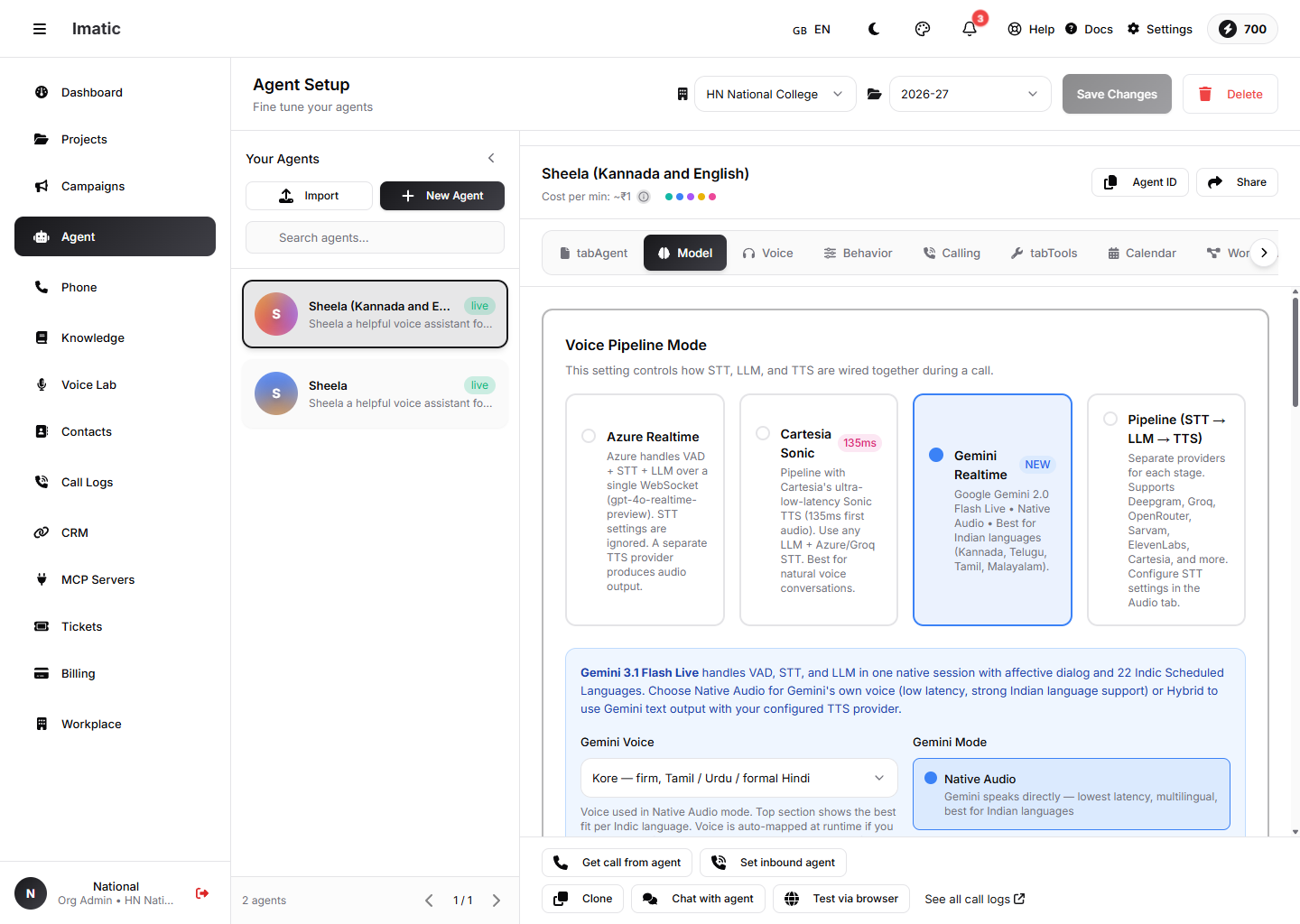 Model टैब: एक Voice Pipeline Mode चुनें — Azure Realtime, Cartesia Sonic, Gemini Realtime, या एक अलग STT→LLM→TTS Pipeline।
Model टैब: एक Voice Pipeline Mode चुनें — Azure Realtime, Cartesia Sonic, Gemini Realtime, या एक अलग STT→LLM→TTS Pipeline।
यह टैब की सबसे महत्वपूर्ण सेटिंग है — यह नियंत्रित करती है कि किसी कॉल के दौरान STT, LLM और TTS एक साथ कैसे जुड़े हैं। चार मोड में से एक चुनें:
- Azure Realtime (डिफ़ॉल्ट) — Azure एक
gpt-4o-realtime-previewपरिनियोजन का उपयोग करते हुए एक ही WebSocket पर voice-activity detection, speech-to-text और LLM संभालता है। Audio टैब पर STT सेटिंग्स को अनदेखा किया जाता है; एक अलग TTS प्रदाता ऑडियो उत्पन्न करता है। - Cartesia Sonic — एक पाइपलाइन जो Cartesia के अति-निम्न-विलंब Sonic TTS का उपयोग करती है, किसी भी LLM और एक Azure/Groq STT के साथ।
- Gemini Realtime — Google Gemini Live मूल रूप से VAD, STT और LLM संभालता है, भारतीय भाषाओं के लिए मज़बूत समर्थन के साथ। यह अपनी खुद की वॉयस (Native Audio) से बोल सकता है या आपके कॉन्फ़िगर किए गए TTS के लिए टेक्स्ट आउटपुट कर सकता है (Hybrid)।
- Pipeline (STT → LLM → TTS) — प्रत्येक चरण के लिए अलग प्रदाता, स्वतंत्र रूप से कॉन्फ़िगर। इसका उपयोग तब करें जब आप ट्रांसक्राइबर, मॉडल और वॉयस पर पूर्ण नियंत्रण चाहते हैं।
प्रत्येक realtime मोड को मॉडलों के एक विशिष्ट परिवार की आवश्यकता होती है, और मॉडल सीधे realtime प्रदाता को पास किया जाता है — एक असंगत मान कॉल के समय विफल हो जाता है। जब आप मोड बदलते हैं तो बिल्डर स्वतः एक संगत मॉडल सेट करता है, और सहेजने पर यह मॉडल को मोड के अनुरूप मिलाता है। विशेष रूप से, gpt-4 जैसा एक सादा चैट मॉडल डिफ़ॉल्ट Azure Realtime मोड के लिए मान्य नहीं है और सहेजने पर पुनः लिखा जाता है; realtime मोड के लिए एक realtime परिनियोजन चुनें, और Pipeline / Cartesia Sonic के लिए एक chat-completion मॉडल।
प्रदाता और मॉडल चुनें
पूर्ण-प्रबंधित realtime मोड के बाहर, आप LLM प्रदाता और फिर उस प्रदाता के लिए एक मॉडल चुनते हैं। प्रदाता सूची केवल वे प्रदाता दिखाती है जिनके लिए आपके संगठन ने क्रेडेंशियल सक्षम किए हैं (Settings में कॉन्फ़िगर)। क्या सक्षम है इसके आधार पर, इसमें अन्य के साथ-साथ Azure OpenAI, Google Gemini, Groq, OpenRouter और Sarvam शामिल हो सकते हैं।
- Azure के लिए, मॉडल विकल्प आपके कॉन्फ़िगर किए गए परिनियोजनों से आते हैं (प्रत्येक क्रेडेंशियल एक परिनियोजन है)।
- एकल-कुंजी प्रदाताओं के लिए, मॉडल सूची प्लेटफ़ॉर्म के मॉडल कैटलॉग से आती है।
वह मॉडल चुनें जो काम के अनुकूल हो: उच्च-क्षमता वाले मॉडल जटिल कॉलों पर बेहतर तर्क करते हैं, जबकि हल्के मॉडल तेज़ी से जवाब देते हैं और प्रति कॉल कम खर्च करते हैं। अधिकांश कॉलिंग एजेंटों के लिए, विलंब उतना ही मायने रखता है जितना कच्ची गुणवत्ता।
मॉडल पैरामीटर
Model Parameters अनुभाग निर्माण को नियंत्रित करता है:
- टोकन — प्रति बारी मॉडल कितना उत्पन्न करता है इसे सीमित करता है। इसे मामूली रखें ताकि एजेंट फ़ोन कॉल पर बकवास न करे।
- तापमान — उत्तर कितने विविध हैं। स्क्रिप्टेड, अनुपालन-संवेदनशील कॉलों के लिए कम; संवादात्मक संपर्क के लिए अधिक।
- Top P — nucleus-sampling कटऑफ़, विविधता नियंत्रित करने का एक वैकल्पिक तरीका।
- आवृत्ति दंड और उपस्थिति दंड — दोहराव को हतोत्साहित करते हैं और मॉडल को नए विषय पेश करने के लिए प्रोत्साहित करते हैं।
उन्नत सेटिंग्स
Advanced Settings अनुभाग परिचालन नियंत्रण जोड़ता है:
- टाइमआउट (ms) — किसी बारी पर हार मानने से पहले मॉडल का कितनी देर इंतज़ार करना है।
- पुनः प्रयास गणना और पुनः प्रयास विलंब (ms) — एजेंट किसी विफल अनुरोध का पुनः प्रयास कैसे करता है।
- प्रतिक्रिया प्रारूप — Text या JSON।
- स्ट्रीम सक्षम — कम अनुभूत विलंब के लिए टोकन को उत्पन्न होते ही स्ट्रीम करें (डिफ़ॉल्ट रूप से चालू)।
- JSON मोड — संरचित JSON आउटपुट बाध्य करें।
- लागत ट्रैकिंग — इस एजेंट के लिए टोकन खर्च रिकॉर्ड करें।
आप Custom Parameters के अंतर्गत कच्चे JSON के रूप में अतिरिक्त प्रदाता पैरामीटर भी प्रदान कर सकते हैं।
फ़ॉलबैक मॉडल
एक फ़ॉलबैक प्रदाता और मॉडल सेट करें ताकि प्राथमिक के अनुपलब्ध होने पर कॉल काम करती रहें। यदि प्राथमिक जवाब नहीं दे सकता, तो एजेंट बातचीत छोड़ने के बजाय फ़ॉलबैक का उपयोग करता है — किसी एजेंट को लचीला बनाने का सबसे सरल तरीका।
ज्ञान आधार और RAG
पुनर्प्राप्ति-संवर्धित निर्माण यहाँ, LLM टैब पर, Add Knowledge Base अनुभाग में कॉन्फ़िगर होता है। RAG Enabled चालू करें, एक या अधिक ज्ञान आधार चुनें, और RAG Top K (कितने अंश पुनर्प्राप्त करने हैं) और समानता सीमा (किसी अंश को कितना करीबी मेल खाना चाहिए) ट्यून करें। इन्हें कैसे ट्यून करें और पहले एक ज्ञान आधार कैसे बनाएँ इसके लिए ज्ञान और RAG देखें।
उपयोग और लागत ट्रैक करना
मॉडल उपयोग आपके संगठन के प्रीपेड बैलेंस से क्रेडिट खर्च करता है। अपने एजेंटों में खपत और खर्च देखने के लिए, बिलिंग का उपयोग करें — Overview योजना और उपयोग दिखाता है, और Wallet आपका प्रीपेड क्रेडिट, टॉप-अप और इतिहास दिखाता है। कुशल मॉडल और समझदार टोकन सीमाएँ चुनना लागत नियंत्रित करने का सबसे सीधा तरीका है।