Modelo de lenguaje (LLM)
La pestaña LLM decide cómo piensa tu agente y cómo está cableado su pipeline de voz. Controla el modo de pipeline de voz (cómo encajan la voz a texto, el modelo de lenguaje y el texto a voz), qué proveedor y modelo de LLM impulsan la conversación, los parámetros de generación, un modelo de respaldo y la vinculación de RAG / base de conocimiento. Configura esto en el constructor de agentes en /agent/setup.
Modo de pipeline de voz
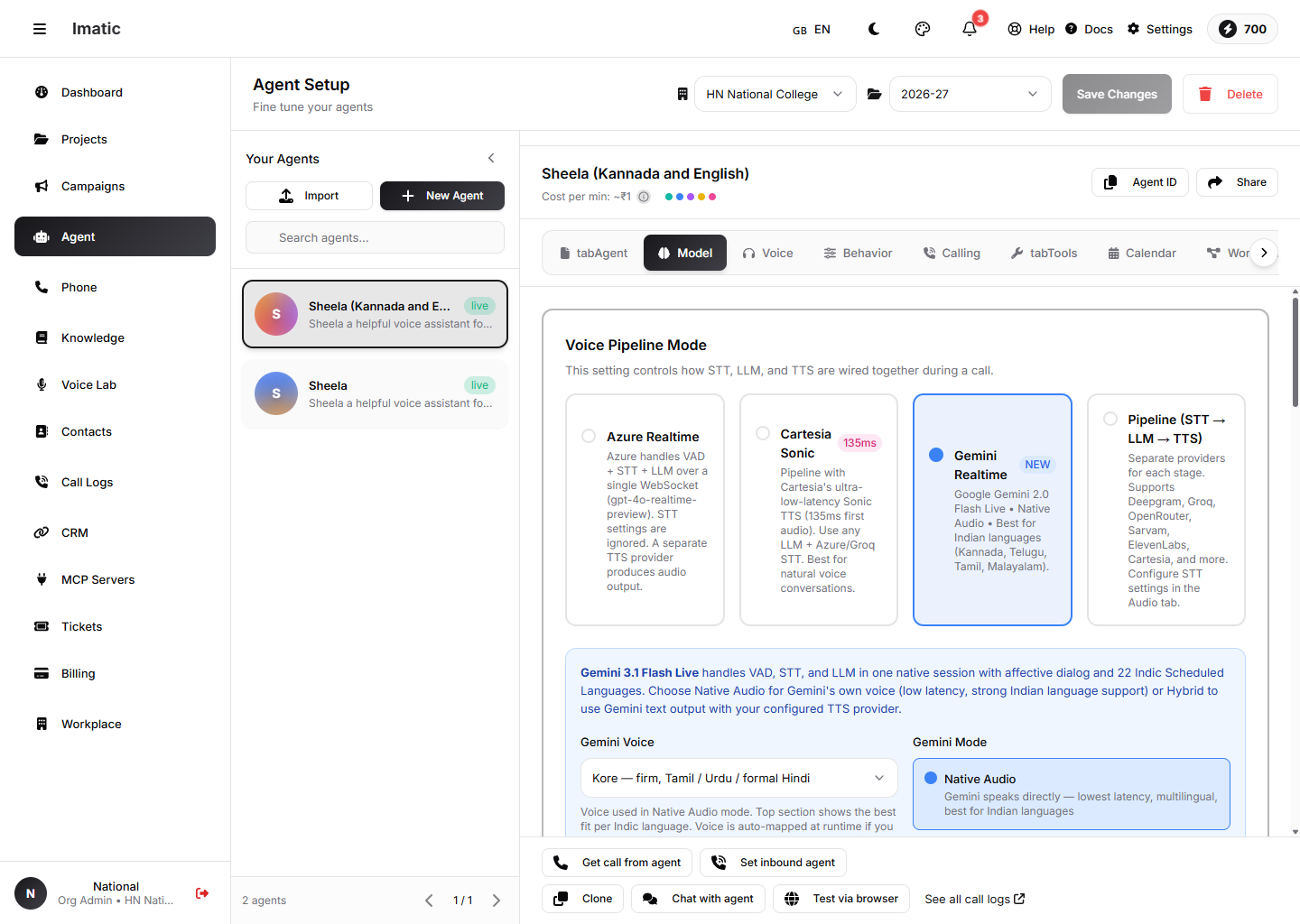 La pestaña Model: elige un Voice Pipeline Mode — Azure Realtime, Cartesia Sonic, Gemini Realtime, o un Pipeline STT→LLM→TTS separado.
La pestaña Model: elige un Voice Pipeline Mode — Azure Realtime, Cartesia Sonic, Gemini Realtime, o un Pipeline STT→LLM→TTS separado.
Este es el ajuste más importante de la pestaña — controla cómo se cablean STT, el LLM y TTS durante una llamada. Elige uno de cuatro modos:
- Azure Realtime (predeterminado) — Azure maneja la detección de actividad de voz, la voz a texto y el LLM sobre un único WebSocket usando un despliegue
gpt-4o-realtime-preview. Los ajustes de STT en la pestaña Audio se ignoran; un proveedor de TTS separado produce el audio. - Cartesia Sonic — un pipeline que usa el TTS Sonic de ultra baja latencia de Cartesia, con cualquier LLM y un STT de Azure/Groq.
- Gemini Realtime — Google Gemini Live maneja VAD, STT y el LLM de forma nativa, con fuerte soporte para idiomas indios. Puede hablar con su propia voz (Native Audio) o producir texto para tu TTS configurado (Hybrid).
- Pipeline (STT → LLM → TTS) — proveedores separados para cada etapa, configurados de forma independiente. Úsalo cuando quieras control total sobre el transcriptor, el modelo y la voz.
Cada modo de tiempo real requiere una familia específica de modelos, y el modelo se pasa directamente al proveedor de tiempo real — un valor incompatible falla en el momento de la llamada. Cuando cambias de modo, el constructor configura automáticamente un modelo compatible, y al guardar reconcilia el modelo con el modo. En particular, un modelo de chat simple como gpt-4 no es válido para el modo Azure Realtime predeterminado y se reescribe al guardar; elige un despliegue de tiempo real para los modos de tiempo real, y un modelo de chat-completion para Pipeline / Cartesia Sonic.
Elige el proveedor y el modelo
Fuera de los modos de tiempo real totalmente gestionados, eliges el proveedor de LLM y luego un modelo para ese proveedor. La lista de proveedores muestra solo los proveedores para los que tu organización ha habilitado credenciales (configuradas en Ajustes). Según lo que esté habilitado, eso puede incluir Azure OpenAI, Google Gemini, Groq, OpenRouter y Sarvam.
- Para Azure, las opciones de modelo provienen de tus despliegues configurados (cada credencial es un despliegue).
- Para los proveedores de clave única, la lista de modelos proviene del catálogo de modelos de la plataforma.
Elige el modelo que se ajuste al trabajo: los modelos de mayor capacidad razonan mejor en llamadas complejas, mientras que los modelos más ligeros responden más rápido y cuestan menos por llamada. Para la mayoría de los agentes de llamadas, la latencia importa tanto como la calidad bruta.
Parámetros del modelo
La sección Parámetros del modelo controla la generación:
- Tokens — limita cuánto genera el modelo por turno. Mantenlo modesto para que el agente no divague en una llamada telefónica.
- Temperatura — cuán variadas son las respuestas. Baja para llamadas con guion y sensibles al cumplimiento; más alta para alcance conversacional.
- Top P — corte de muestreo por núcleo, una forma alternativa de controlar la variedad.
- Penalización de frecuencia y penalización de presencia — desalientan la repetición y animan al modelo a introducir nuevos temas.
Ajustes avanzados
La sección Ajustes avanzados agrega controles operativos:
- Tiempo de espera (ms) — cuánto esperar al modelo antes de abandonar un turno.
- Recuento de reintentos y retardo de reintento (ms) — cómo reintenta el agente una solicitud fallida.
- Formato de respuesta — Texto o JSON.
- Streaming habilitado — transmite tokens a medida que se generan (activado por defecto) para una menor latencia percibida.
- Modo JSON — fuerza una salida JSON estructurada.
- Seguimiento de costes — registra el gasto de tokens de este agente.
También puedes proporcionar parámetros de proveedor adicionales como JSON crudo en Parámetros personalizados.
Modelo de respaldo
Configura un proveedor y modelo de respaldo para que las llamadas sigan funcionando si el principal no está disponible. Si el principal no puede responder, el agente usa el respaldo en lugar de abandonar la conversación — la forma más sencilla de hacer un agente resiliente.
Base de conocimiento y RAG
La generación aumentada por recuperación se configura aquí, en la pestaña LLM, en la sección Agregar base de conocimiento. Activa RAG habilitado, selecciona una o más bases de conocimiento, y ajusta RAG Top K (cuántos pasajes recuperar) y el umbral de similitud (cuán cerca debe coincidir un pasaje). Consulta Conocimiento y RAG para saber cómo ajustar esto y cómo construir primero una base de conocimiento.
Seguimiento del uso y el coste
El uso del modelo consume créditos del saldo prepagado de tu organización. Para ver el consumo y el gasto en tus agentes, usa Facturación — la Visión general muestra el plan y el uso, y la Cartera muestra tu crédito prepagado, recargas e historial. Elegir modelos eficientes y límites de tokens sensatos es la forma más directa de controlar el coste.