Conocimiento y RAG
La generación aumentada por recuperación (RAG) permite que tu agente responda a partir de tus propios documentos en lugar de adivinar: cuando quien llama pregunta algo, el agente busca los pasajes más relevantes y responde a partir de ellos. RAG se configura en la sección Agregar base de conocimiento de la pestaña LLM en el constructor de agentes en /agent/setup — no hay una pestaña de Conocimiento separada.
Cómo funciona RAG aquí
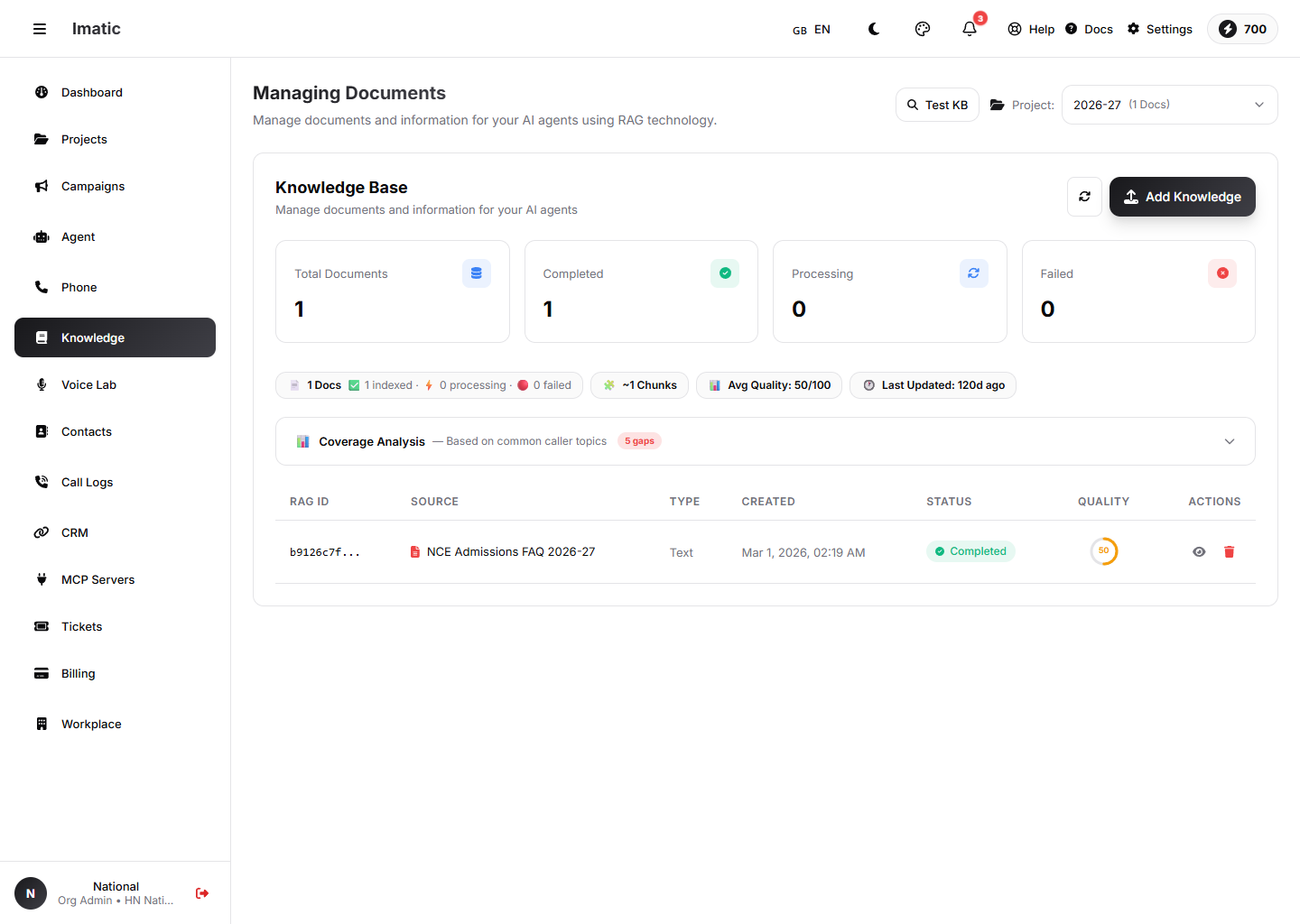 Una base de conocimiento: los documentos se dividen en fragmentos, se indexan y se recuperan durante la llamada, con análisis de calidad y cobertura.
Una base de conocimiento: los documentos se dividen en fragmentos, se indexan y se recuperan durante la llamada, con análisis de calidad y cobertura.
RAG mantiene las respuestas fundamentadas. En lugar de basarse solo en lo que el modelo ya sabe, el agente recupera contenido coincidente de tus documentos y lo usa para responder. Eso significa respuestas precisas y actualizadas sobre tus productos, políticas y procesos — y muchas menos respuestas inventadas.
Antes de poder vincular una base de conocimiento, necesitas una. Sube tus documentos (PDF, DOCX o TXT) y gestiónalos en la Base de conocimiento.
Antes de vincular
Necesitas una base de conocimiento con contenido antes de que RAG haga algo. El orden es:
- Sube e indexa tus documentos en la Base de conocimiento.
- En la pestaña LLM, activa RAG habilitado y vincula esa base de conocimiento al agente.
- Ajusta el umbral de similitud y top-k abajo.
- Prueba con preguntas reales y ajusta.
Vincular una base de conocimiento
En la pestaña LLM, activa RAG habilitado y selecciona la base de conocimiento (o varias) de la que quieres que este agente se nutra. Una vez vinculada, el agente la busca automáticamente durante las llamadas y usa lo que encuentra para responder.
Umbral de similitud
El umbral de similitud establece cuán cerca debe coincidir un pasaje con la pregunta de quien llama antes de usarse.
- Un umbral más alto devuelve solo coincidencias fuertes — más preciso, pero el agente puede no encontrar nada para preguntas formuladas de forma vaga.
- Un umbral más bajo es más permisivo y muestra más pasajes, con el riesgo de incorporar algunos menos relevantes.
Ajústalo para que el agente encuentre tu contenido de forma fiable sin arrastrar ruido.
Top-k
Top-k establece cuántos de los pasajes mejor coincidentes recupera el agente para cada pregunta.
- Un top-k más pequeño mantiene las respuestas ceñidas y enfocadas en las coincidencias más cercanas.
- Un top-k más grande da al agente más contexto con el que trabajar, lo que ayuda en preguntas amplias pero puede diluir la respuesta.
Empieza con valores conservadores, luego prueba con preguntas reales en la prueba de chat en /agent/chat. Si el agente pierde respuestas que claramente están en tus documentos, baja el umbral o sube un poco el top-k; si incorpora contenido fuera de tema, haz lo contrario.
Ajuste de un vistazo
Cuando el agente no responde como quieres, estos dos síntomas cubren la mayoría de los casos:
| Síntoma | Causa probable | Prueba |
|---|---|---|
| El agente dice que no sabe, pero la respuesta está en tus documentos | Umbral demasiado estricto, o top-k demasiado pequeño | Baja el umbral de similitud, o sube un poco el top-k |
| El agente incorpora material fuera de tema o incorrecto | Umbral demasiado laxo, o top-k demasiado grande | Sube el umbral de similitud, o baja el top-k |
Cambia un ajuste a la vez y vuelve a probar, para que puedas saber qué movió realmente el resultado.