ভাষা মডেল (LLM)
LLM ট্যাব নির্ধারণ করে আপনার এজেন্ট কীভাবে চিন্তা করে এবং এর voice pipeline কীভাবে যুক্ত। এটি voice pipeline mode (speech-to-text, ভাষা মডেল এবং text-to-speech কীভাবে একসাথে মিলে যায়), কোন LLM provider and model কথোপকথন চালায়, জেনারেশন প্যারামিটার, একটি ফলব্যাক মডেল, এবং RAG / জ্ঞান-ভিত্তি সংযোগ নিয়ন্ত্রণ করে। এটি /agent/setup-এ এজেন্ট বিল্ডারে সেট করুন।
Voice pipeline mode
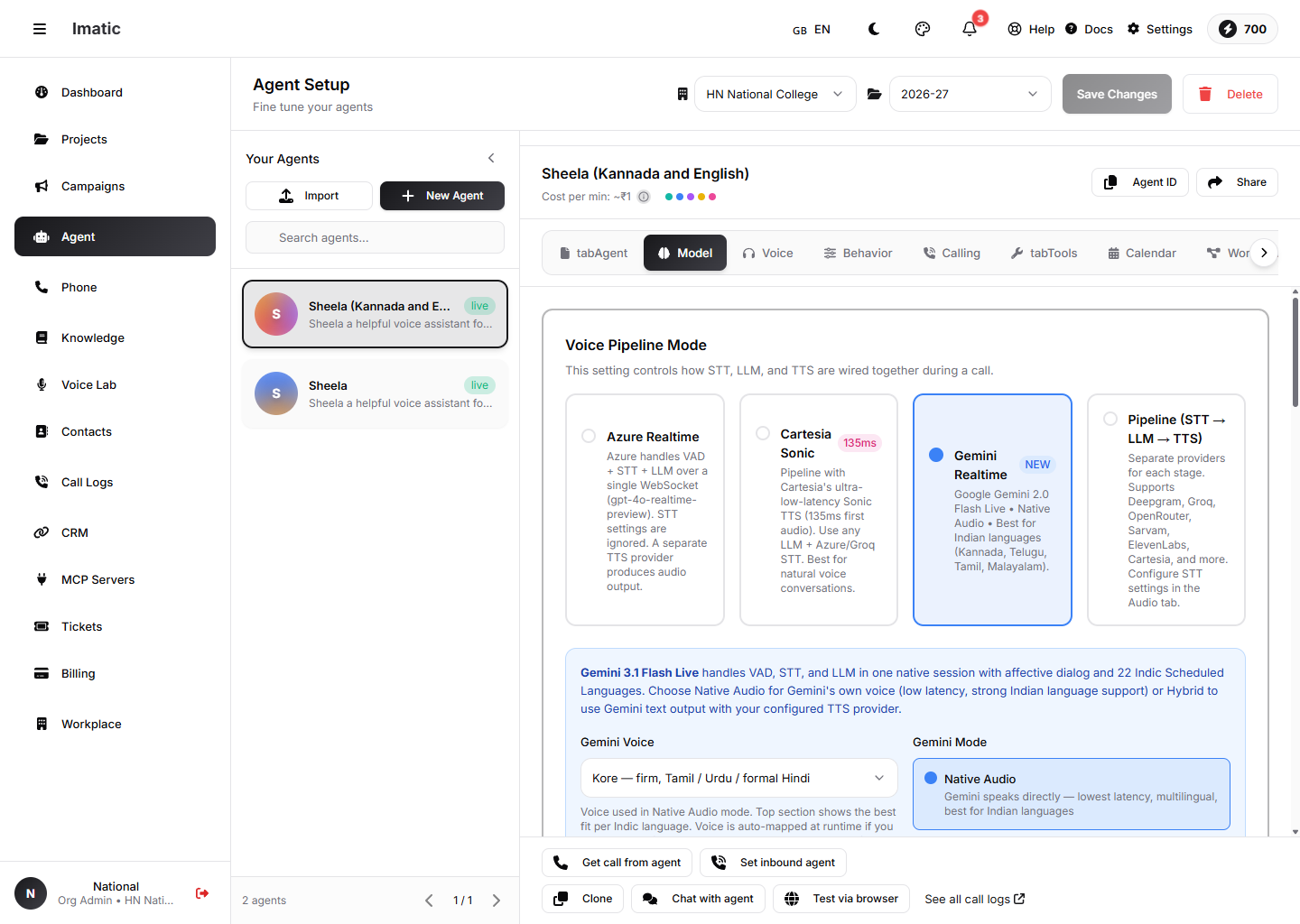 Model ট্যাব: একটি Voice Pipeline Mode বেছে নিন — Azure Realtime, Cartesia Sonic, Gemini Realtime, অথবা একটি পৃথক STT→LLM→TTS Pipeline।
Model ট্যাব: একটি Voice Pipeline Mode বেছে নিন — Azure Realtime, Cartesia Sonic, Gemini Realtime, অথবা একটি পৃথক STT→LLM→TTS Pipeline।
এটি ট্যাবের সবচেয়ে গুরুত্বপূর্ণ সেটিং — এটি নিয়ন্ত্রণ করে একটি কলের সময় STT, LLM এবং TTS কীভাবে একসাথে যুক্ত হয়। চারটি মোডের একটি বেছে নিন:
- Azure Realtime (ডিফল্ট) — Azure একটি
gpt-4o-realtime-previewডিপ্লয়মেন্ট ব্যবহার করে একটি একক WebSocket-এর মাধ্যমে voice-activity detection, speech-to-text এবং LLM পরিচালনা করে। Audio ট্যাবের STT সেটিংস উপেক্ষা করা হয়; একটি পৃথক TTS প্রদানকারী অডিও তৈরি করে। - Cartesia Sonic — একটি পাইপলাইন যা যেকোনো LLM এবং একটি Azure/Groq STT সহ Cartesia-এর অতি-নিম্ন-লেটেন্সি Sonic TTS ব্যবহার করে।
- Gemini Realtime — Google Gemini Live নেটিভভাবে VAD, STT এবং LLM পরিচালনা করে, ভারতীয় ভাষার জন্য শক্তিশালী সমর্থন সহ। এটি নিজের ভয়েসে কথা বলতে পারে (Native Audio) অথবা আপনার কনফিগার করা TTS-এর জন্য টেক্সট আউটপুট করতে পারে (Hybrid)।
- Pipeline (STT → LLM → TTS) — প্রতিটি পর্যায়ের জন্য পৃথক প্রদানকারী, স্বাধীনভাবে কনফিগার করা। আপনি যখন ট্রান্সক্রাইবার, মডেল এবং ভয়েসের উপর সম্পূর্ণ নিয়ন্ত্রণ চান তখন এটি ব্যবহার করুন।
প্রতিটি realtime মোডের একটি নির্দিষ্ট মডেল পরিবার প্রয়োজন, এবং মডেলটি সরাসরি realtime প্রদানকারীর কাছে পাস করা হয় — একটি অসংগত মান কল করার সময় ব্যর্থ হয়। আপনি যখন মোড পরিবর্তন করেন বিল্ডার স্বয়ংক্রিয়ভাবে একটি সামঞ্জস্যপূর্ণ মডেল সেট করে, এবং সংরক্ষণের সময় এটি মডেলকে মোডের সাথে মিলিয়ে নেয়। বিশেষ করে, gpt-4-এর মতো একটি সাধারণ চ্যাট মডেল ডিফল্ট Azure Realtime মোডের জন্য বৈধ নয় এবং সংরক্ষণের সময় পুনর্লিখিত হয়; realtime মোডের জন্য একটি realtime ডিপ্লয়মেন্ট বেছে নিন, এবং Pipeline / Cartesia Sonic-এর জন্য একটি chat-completion মডেল।
প্রদানকারী এবং মডেল বেছে নিন
সম্পূর্ণ-পরিচালিত realtime মোডের বাইরে, আপনি LLM provider এবং তারপর সেই প্রদানকারীর জন্য একটি model বাছেন। প্রদানকারী তালিকা শুধুমাত্র সেই প্রদানকারীদের দেখায় যাদের ক্রেডেনশিয়াল আপনার প্রতিষ্ঠান সক্ষম করেছে (Settings-এ কনফিগার করা)। কী সক্ষম তার উপর নির্ভর করে, এতে অন্যান্যের মধ্যে Azure OpenAI, Google Gemini, Groq, OpenRouter এবং Sarvam অন্তর্ভুক্ত থাকতে পারে।
- Azure-এর জন্য, মডেল অপশনগুলি আপনার কনফিগার করা ডিপ্লয়মেন্ট থেকে আসে (প্রতিটি ক্রেডেনশিয়াল একটি ডিপ্লয়মেন্ট)।
- single-key প্রদানকারীদের জন্য, মডেল তালিকা প্ল্যাটফর্মের মডেল ক্যাটালগ থেকে আসে।
কাজের সাথে মানানসই মডেল বেছে নিন: উচ্চ-ক্ষমতার মডেল জটিল কলে ভালো যুক্তি করে, যখন হালকা মডেল দ্রুত প্রতিক্রিয়া জানায় এবং প্রতি কলে কম খরচ করে। বেশিরভাগ কলিং এজেন্টের জন্য, কাঁচা গুণমানের মতোই লেটেন্সি গুরুত্বপূর্ণ।
মডেল প্যারামিটার
Model Parameters বিভাগ জেনারেশন নিয়ন্ত্রণ করে:
- Tokens — প্রতি টার্নে মডেল কতটা তৈরি করে তা সীমাবদ্ধ করে। এটি পরিমিত রাখুন যাতে এজেন্ট ফোন কলে অযথা কথা না বলে।
- Temperature — উত্তরগুলি কতটা বৈচিত্র্যময়। স্ক্রিপ্টেড, কমপ্লায়েন্স-সংবেদনশীল কলের জন্য নিম্ন; কথোপকথনমূলক আউটরিচের জন্য উচ্চ।
- Top P — nucleus-sampling কাটঅফ, বৈচিত্র্য নিয়ন্ত্রণের একটি বিকল্প উপায়।
- Frequency penalty এবং presence penalty — পুনরাবৃত্তি নিরুৎসাহিত করে এবং মডেলকে নতুন বিষয় উপস্থাপন করতে উৎসাহিত করে।
উন্নত সেটিংস
Advanced Settings বিভাগ অপারেশনাল নিয়ন্ত্রণ যোগ করে:
- Timeout (ms) — একটি টার্ন ছেড়ে দেওয়ার আগে মডেলের জন্য কতক্ষণ অপেক্ষা করতে হবে।
- Retry count এবং retry delay (ms) — এজেন্ট কীভাবে একটি ব্যর্থ অনুরোধ পুনরায় চেষ্টা করে।
- Response format — Text বা JSON।
- Stream enabled — কম অনুভূত লেটেন্সির জন্য টোকেনগুলি তৈরি হওয়ার সাথে সাথে স্ট্রিম করুন (ডিফল্টভাবে চালু)।
- JSON mode — কাঠামোবদ্ধ JSON আউটপুট বাধ্য করুন।
- Cost tracking — এই এজেন্টের জন্য টোকেন ব্যয় রেকর্ড করুন।
আপনি Custom Parameters-এর অধীনে কাঁচা JSON হিসেবে অতিরিক্ত প্রদানকারী প্যারামিটারও সরবরাহ করতে পারেন।
ফলব্যাক মডেল
একটি fallback provider and model সেট করুন যাতে প্রাথমিকটি অনুপলব্ধ হলে কলগুলি কাজ করতে থাকে। প্রাথমিকটি সাড়া দিতে না পারলে, এজেন্ট কথোপকথন বাদ দেওয়ার পরিবর্তে ফলব্যাক ব্যবহার করে — একটি এজেন্টকে স্থিতিস্থাপক করার সবচেয়ে সহজ উপায়।
জ্ঞান ভিত্তি ও RAG
Retrieval-augmented generation এখানে, LLM ট্যাবে, Add Knowledge Base বিভাগে কনফিগার করা হয়। RAG Enabled চালু করুন, এক বা একাধিক জ্ঞান ভিত্তি নির্বাচন করুন, এবং RAG Top K (কতগুলি অনুচ্ছেদ খুঁজে আনতে হবে) এবং similarity threshold (একটি অনুচ্ছেদ কতটা ঘনিষ্ঠভাবে মিলতে হবে) টিউন করুন। এগুলি কীভাবে টিউন করতে হয় এবং প্রথমে একটি জ্ঞান ভিত্তি কীভাবে তৈরি করতে হয় তার জন্য দেখুন জ্ঞান ও RAG।
ব্যবহার এবং খরচ ট্র্যাক করা
মডেল ব্যবহার আপনার প্রতিষ্ঠানের প্রিপেইড ব্যালেন্স থেকে ক্রেডিট খরচ করে। আপনার এজেন্ট জুড়ে খরচ এবং ব্যয় দেখতে Billing ব্যবহার করুন — Overview প্ল্যান এবং ব্যবহার দেখায়, এবং Wallet আপনার প্রিপেইড ক্রেডিট, টপ-আপ এবং ইতিহাস দেখায়। দক্ষ মডেল এবং যুক্তিসঙ্গত টোকেন সীমা বেছে নেওয়া খরচ নিয়ন্ত্রণের সবচেয়ে সরাসরি উপায়।