জ্ঞান ও RAG
Retrieval-augmented generation (RAG) আপনার এজেন্টকে অনুমান করার পরিবর্তে আপনার নিজস্ব নথি থেকে উত্তর দিতে দেয়: যখন একজন কলার কিছু জিজ্ঞাসা করে, এজেন্ট সবচেয়ে প্রাসঙ্গিক অনুচ্ছেদগুলি খুঁজে বের করে এবং সেগুলি থেকে উত্তর দেয়। RAG /agent/setup-এ এজেন্ট বিল্ডারের LLM ট্যাবের Add Knowledge Base বিভাগে কনফিগার করা হয় — কোনো পৃথক Knowledge ট্যাব নেই।
RAG এখানে কীভাবে কাজ করে
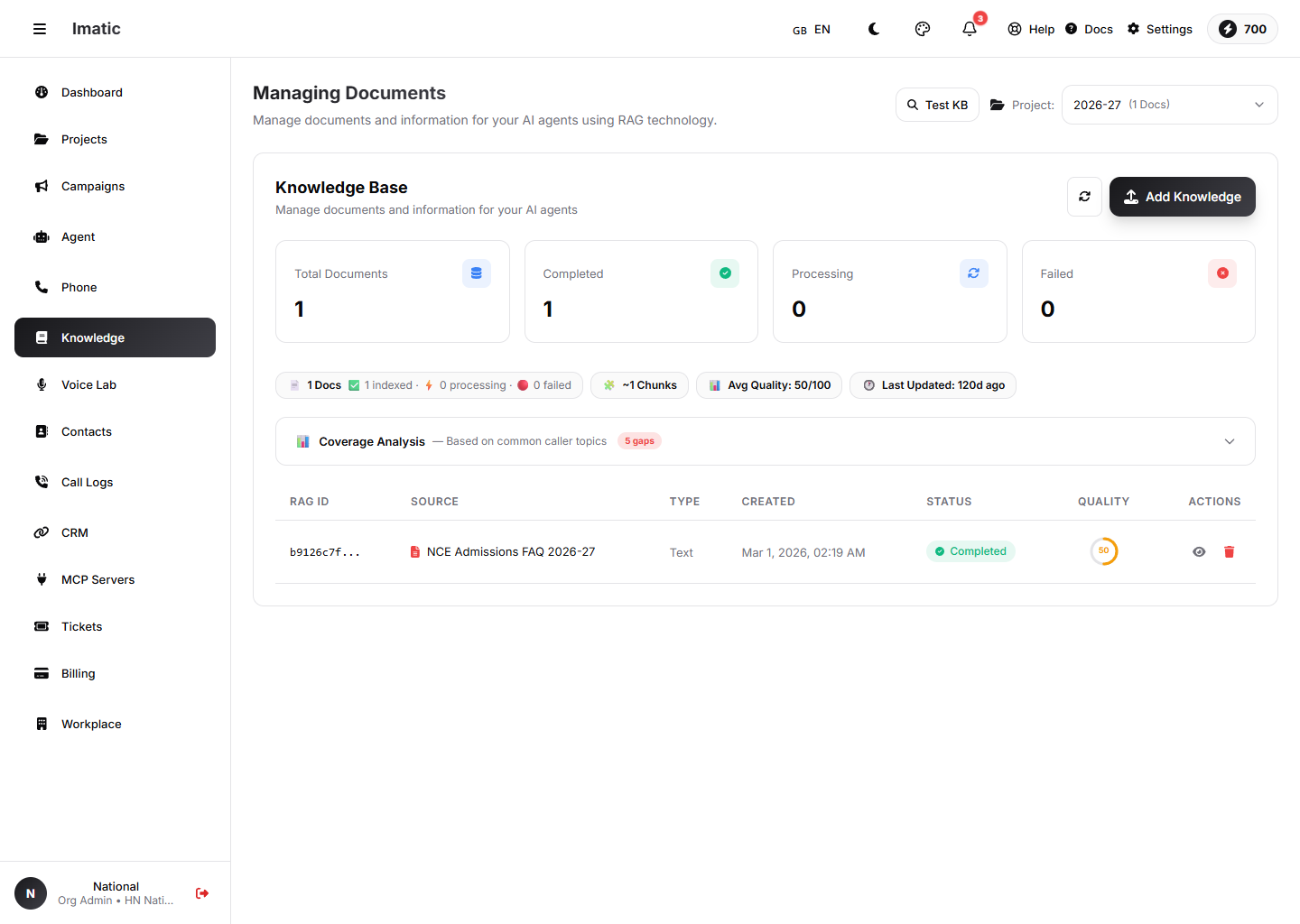 একটি নলেজ বেস: ডকুমেন্টগুলো খণ্ডে বিভক্ত, ইনডেক্সড এবং কলের সময় পুনরুদ্ধার করা হয়, সাথে মান ও কভারেজ বিশ্লেষণ।
একটি নলেজ বেস: ডকুমেন্টগুলো খণ্ডে বিভক্ত, ইনডেক্সড এবং কলের সময় পুনরুদ্ধার করা হয়, সাথে মান ও কভারেজ বিশ্লেষণ।
RAG উত্তরগুলিকে গ্রাউন্ডেড রাখে। মডেল ইতিমধ্যে যা জানে শুধু তার উপর নির্ভর করার পরিবর্তে, এজেন্ট আপনার নথি থেকে মিলে যাওয়া কন্টেন্ট খুঁজে বের করে এবং প্রতিক্রিয়া জানাতে এটি ব্যবহার করে। এর অর্থ আপনার পণ্য, নীতি এবং প্রক্রিয়া সম্পর্কে সঠিক, হালনাগাদ উত্তর — এবং অনেক কম বানানো উত্তর।
আপনি একটি জ্ঞান ভিত্তি লিঙ্ক করার আগে, আপনার একটি প্রয়োজন। আপনার নথিগুলি (PDF, DOCX বা TXT) আপলোড করুন এবং Knowledge base-এ পরিচালনা করুন।
লিঙ্ক করার আগে
RAG কিছু করার আগে আপনার এতে কন্টেন্ট সহ একটি জ্ঞান ভিত্তি প্রয়োজন। ক্রমটি হলো:
১. Knowledge base-এ আপনার নথিগুলি আপলোড এবং ইনডেক্স করুন। ২. LLM ট্যাবে, RAG Enabled চালু করুন এবং সেই জ্ঞান ভিত্তিটি এজেন্টের সাথে link করুন। ৩. নিচের similarity threshold এবং top-k টিউন করুন। ৪. প্রকৃত প্রশ্ন দিয়ে পরীক্ষা করুন এবং সমন্বয় করুন।
একটি জ্ঞান ভিত্তি লিঙ্ক করুন
LLM ট্যাবে, RAG Enabled চালু করুন এবং আপনি এই এজেন্টকে যে জ্ঞান ভিত্তি (বা কয়েকটি) থেকে আঁকতে চান তা select করুন। একবার লিঙ্ক হলে, এজেন্ট স্বয়ংক্রিয়ভাবে কলের সময় এটি অনুসন্ধান করে এবং উত্তর দিতে যা খুঁজে পায় তা ব্যবহার করে।
Similarity threshold
similarity threshold নির্ধারণ করে একটি অনুচ্ছেদ ব্যবহৃত হওয়ার আগে কলারের প্রশ্নের সাথে কতটা ঘনিষ্ঠভাবে মিলতে হবে।
- একটি উচ্চ threshold শুধুমাত্র শক্তিশালী মিল রিটার্ন করে — আরও সুনির্দিষ্ট, কিন্তু এজেন্ট আলগাভাবে শব্দবদ্ধ প্রশ্নের জন্য কিছুই খুঁজে নাও পেতে পারে।
- একটি নিম্ন threshold আরও ক্ষমাশীল এবং আরও অনুচ্ছেদ প্রকাশ করে, কম প্রাসঙ্গিকগুলি টেনে আনার ঝুঁকিতে।
এটি টিউন করুন যাতে এজেন্ট শব্দ টেনে না এনে নির্ভরযোগ্যভাবে আপনার কন্টেন্ট খুঁজে পায়।
Top-k
Top-k নির্ধারণ করে এজেন্ট প্রতিটি প্রশ্নের জন্য সবচেয়ে ভালো মিলে যাওয়া অনুচ্ছেদগুলির কতগুলি খুঁজে আনে।
- একটি ছোট top-k উত্তরগুলিকে আঁটসাঁট এবং নিকটতম মিলের উপর ফোকাসড রাখে।
- একটি বড় top-k এজেন্টকে কাজ করার জন্য আরও প্রসঙ্গ দেয়, যা বিস্তৃত প্রশ্নের জন্য সাহায্য করে কিন্তু উত্তর পাতলা করতে পারে।
রক্ষণশীল মান দিয়ে শুরু করুন, তারপর /agent/chat-এ চ্যাট পরীক্ষায় প্রকৃত প্রশ্ন দিয়ে পরীক্ষা করুন। যদি এজেন্ট স্পষ্টভাবে আপনার নথিতে থাকা উত্তরগুলি মিস করে, threshold কমান বা top-k একটু বাড়ান; যদি এটি বিষয়-বহির্ভূত কন্টেন্ট টেনে আনে, তার বিপরীত করুন।
এক নজরে টিউনিং
যখন এজেন্ট আপনার পছন্দমতো উত্তর দিচ্ছে না, এই দুটি উপসর্গ বেশিরভাগ ক্ষেত্রে কভার করে:
| উপসর্গ | সম্ভাব্য কারণ | চেষ্টা করুন |
|---|---|---|
| এজেন্ট বলে এটি জানে না, কিন্তু উত্তর আপনার ডকে আছে | threshold খুব কঠোর, বা top-k খুব ছোট | similarity threshold কমান, বা top-k সামান্য বাড়ান |
| এজেন্ট বিষয়-বহির্ভূত বা ভুল উপাদান টেনে আনে | threshold খুব আলগা, বা top-k খুব বড় | similarity threshold বাড়ান, বা top-k কমান |
একবারে একটি সেটিং পরিবর্তন করুন এবং পুনরায় পরীক্ষা করুন, যাতে আপনি বলতে পারেন প্রকৃতপক্ষে কী ফলাফল সরিয়েছে।